

























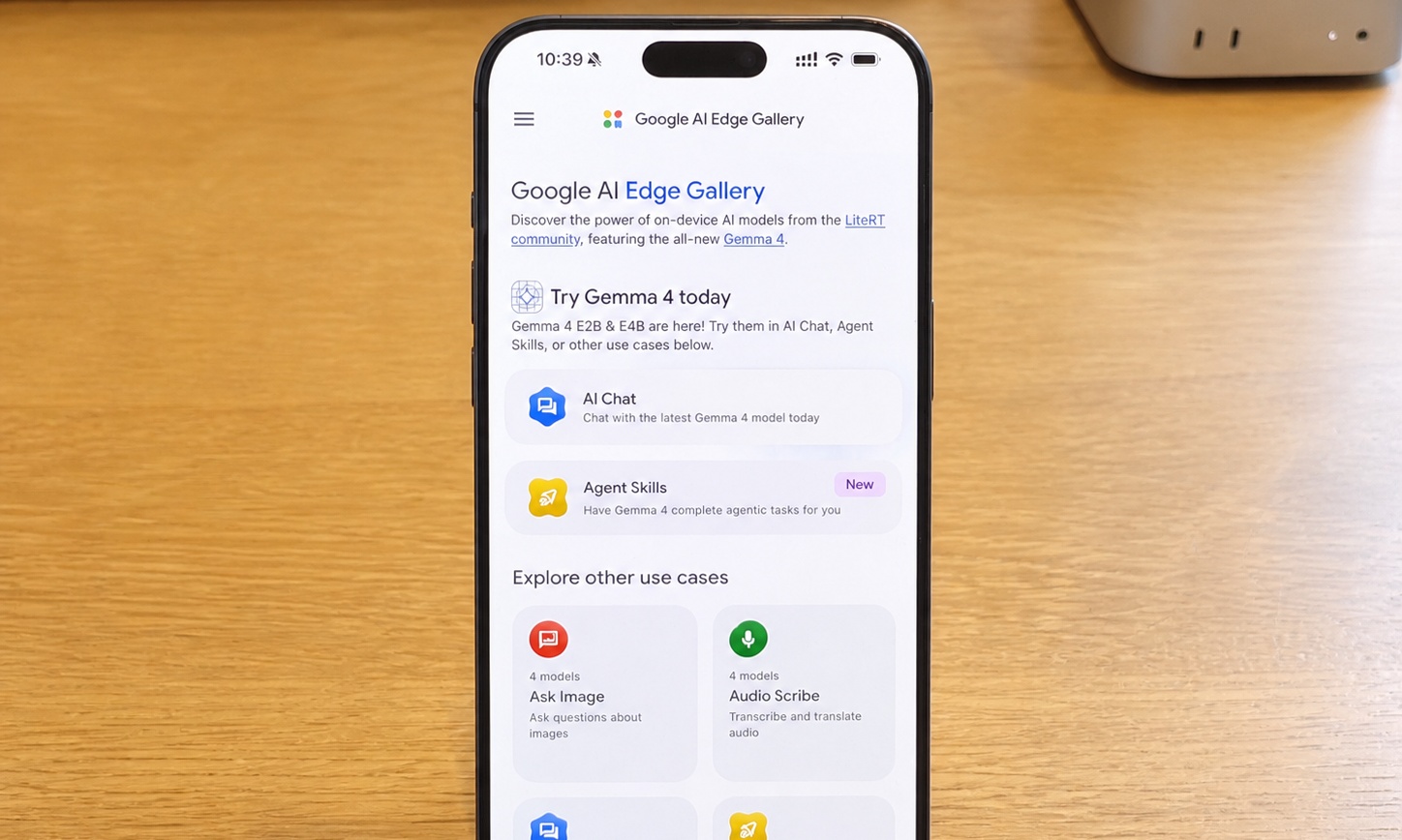

近期,谷歌发布新一代开源模型Gemma 4,包括E2B、E4B、26B、31B四个规格,其中两个「小模型」E2B和E4B,可以直接在智能手机、树莓派等端侧设备部署和离线运行。
谷歌Gemma 4两款「小模型」一经推出,就被不少人誉为迄今为止最好用的端侧模型。雷科技(ID:leitech)也先后发了两篇实测内容:一篇聚集逻辑推理和多模态能力,一篇聚焦国产千元机上的体验表现。
而在使用一段时间后,雷科技(ID:leitech)编辑小伙伴也有了更多新感受和体会。
图源:雷科技摄制
端侧模型,比百科全书好用100倍
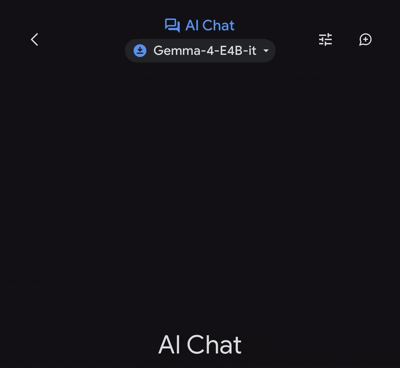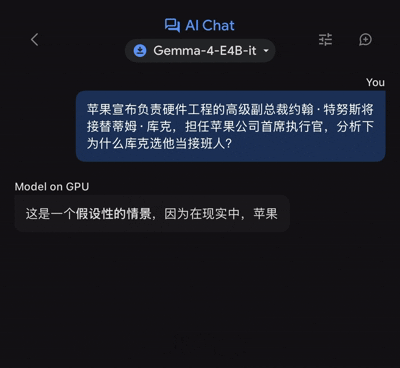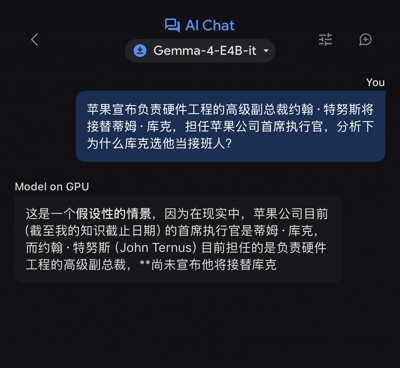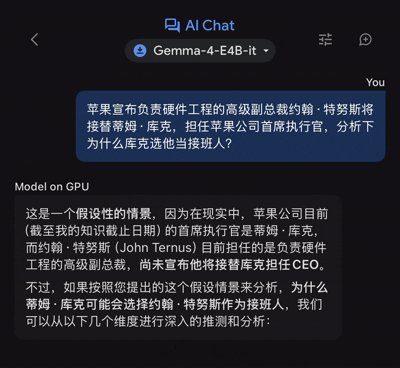
近日,苹果宣布负责硬件工程的高级副总裁约翰·特努斯将接替蒂姆·库克,担任公司首席执行官。其后,国内外连篇累牍的「为何库克选他当接班人?」解读文章,那么把这个问题抛给Gemma 4 E4B,它又能给出怎样的解读呢?
在聊天框输入对应提问后,谷歌的端侧模型的确是接近「零延迟」,立马就开始了信息输出,单说这一体验设定,的确让人眼前一亮。(注:体验设备为iPhone 17 Pro Max,下同)
图源:雷科技
不过,由于输出的文本量不算少,故而前后用了46秒时间,谷歌端侧模型才给出了完整版的答案。

图源:雷科技
粗看之下,已经可以较好解答相当多人的疑问,而这就是端侧模型的核心优势:
在最低的硬件成本(本地运行+0 Token消耗)条件下,给出一个「相对好」的答案,或一个「够用」的解决方案。
今年有部热播国产剧《太平年》,相关的讨论和内容很多,前段时间也抛给了谷歌端侧模型一个问题:
吴越国如何能在重税政策下反而可以维持八十余年的太平繁荣?
这是一个相对专业和细化的问题,不少大学学历(非历史系)的人,都未必了解和清楚,看下E4B模型的水平:

图源:雷科技
可以看出,端侧模型不仅是离线的大百科全书,而且可以根据用户的不同问题乃至方向,去更有侧重地进行解答,包括各类领域的专业问题咨询。
谷歌Gemma 4 E4B模型的知识截止点时间为2023年10月,在此之前发生的所有被记录和公开的事件、科学发现、历史信息和文化知识等,理论来说你都可以问它。
雷科技(ID:leitech)认为,这也是端侧模型作为工具应用,在当下比较有用的一大使用场景,尤其是对古今中外各类信息和知识感兴趣和有好奇心的用户群体。
而在初步体验了这款App(Google AI Edge Gallery)后,雷科技(ID:leitech)编辑就把其放在了手机主屏的Dock底栏,因为几乎天天都用得到。
值得一提的是,谷歌表示虽然Gemma 4的核心训练数据有一个知识截止点,但其系统会不断进行更新和微调,以提高模型的理解和回答能力水平。
处理简单问题,端侧模型事故频发
本以为,在基础知识领域,端侧AI模型已经可以完全胜任,结果现实给了重重一锤。
Gemma 4 E4B模型,连唐诗名篇《将进酒》,都可以给错全文和作者信息。

图源:雷科技
原因很简单,端侧模型整体参数量偏小,发展至今,依然无法涵盖所有知识领域,强如谷歌Gemma 4也如此,所以不少领域的细节信息也就会出现「失真」和「幻觉」现象。
对于这类的古诗文、古籍或资料信息,与其去问端侧模型相应的原始文本信息,不如把原始文本信息直接丢给它,例如古诗或文言文等,然后让其给出翻译或解读内容。
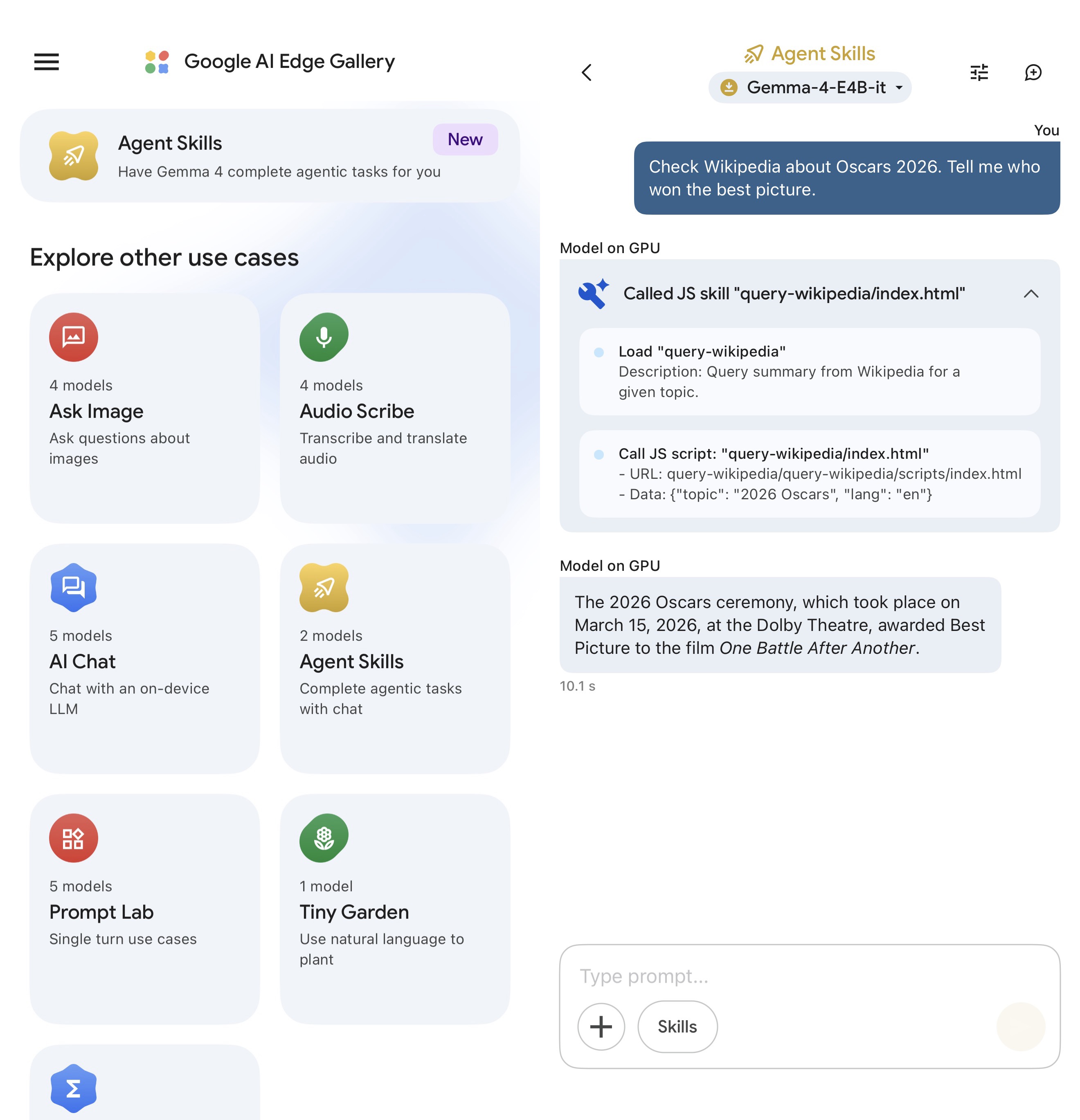
基于端侧模型参数量小带来的知识库信息量少问题,谷歌也尝试在端侧模型上首次引入了「智能体」能力。
不过关于信息检索类的,目前只能联网到在线百科网站(例如维基百科等),并没有提供可以下载的作为「增量」的各类离线知识库资源。
图源:雷科技
除了常规的知识信息问答,以Gemma 4 E2B/E4B等为代表的端侧AI模型,也在发力工作协助和干活场景。
工具应用层面,本以为检查文章基本语病这类工作,完全可以丢给端侧模型去进行协助,但实际表现同样不能让人放心,尤其是长段落文字的语病检查。
究其原因,像检查语病这类的高精度任务,由于需要大量编辑语料和强语言分布记忆,端侧模型常把检查语病变成了文本修改(润色),或者混淆了两者之间的区别,因为对它来说给出文本润色和修改建议反而更容易。
值得注意的是,当你把「进行基本语病检查和修正」的指令发给端侧模型后,它可能很难「理解到位」,但如果换成「进行基本语病检查(无语病不要改)」的指令,端侧模型的输出结果,就会明了不少。

图源:雷科技
谷歌Gemma 4有system role、function calling等控制能力,但前提是你要把提示模板、任务边界、输出格式等尽量写简单和清晰。
另外,经过实测,虽然Gemma 4原生支持超过140种语言,但在检查长文语病等复杂精细度任务上,英文比中文支持得更好,这可能是因其预训练语料仍以英文为主。
端侧模型更适合专用场景?
除了以上列举情况,雷科技(ID:leitech)此前已体验过Gemma 4 E4B模型的原生多模态(图像、音视频)能力,它可以直接看图识物,也可以听懂简单的音频信息、看懂简单的视频信息。
在离线和网络较差的环境下,发一张相册中的图片,谷歌端侧模型就可以给出图像的基本信息。
例如在飞行场景,如果对机上杂志或报纸上的某张图片有「简单」的解读信息需求,那么就可以直接发给端侧模型,让其尝试进行解答。
至于较复杂的图像、音频信息,目前的端侧模型依然难以理解「更多」的信息量。
图源:雷科技
那么,端侧模型目前最擅长的技能是什么呢?
毫无疑问是这几项:离线翻译、计算器、简单解题和测试训练等工具,以及相对专业领域(包括健康等领域)的基础信息科普、咨询等。
此前,谷歌就基于Gemma 3构建了专用的翻译模型TranslateGemma。而得益于专项训练流程,TranslateGemma 4B模型性能可与规模较大的Gemma 3 12B基准模型性能相媲美。可以期待,谷歌后续很快会推出基于Gemma 4的新一代专用翻译模型。
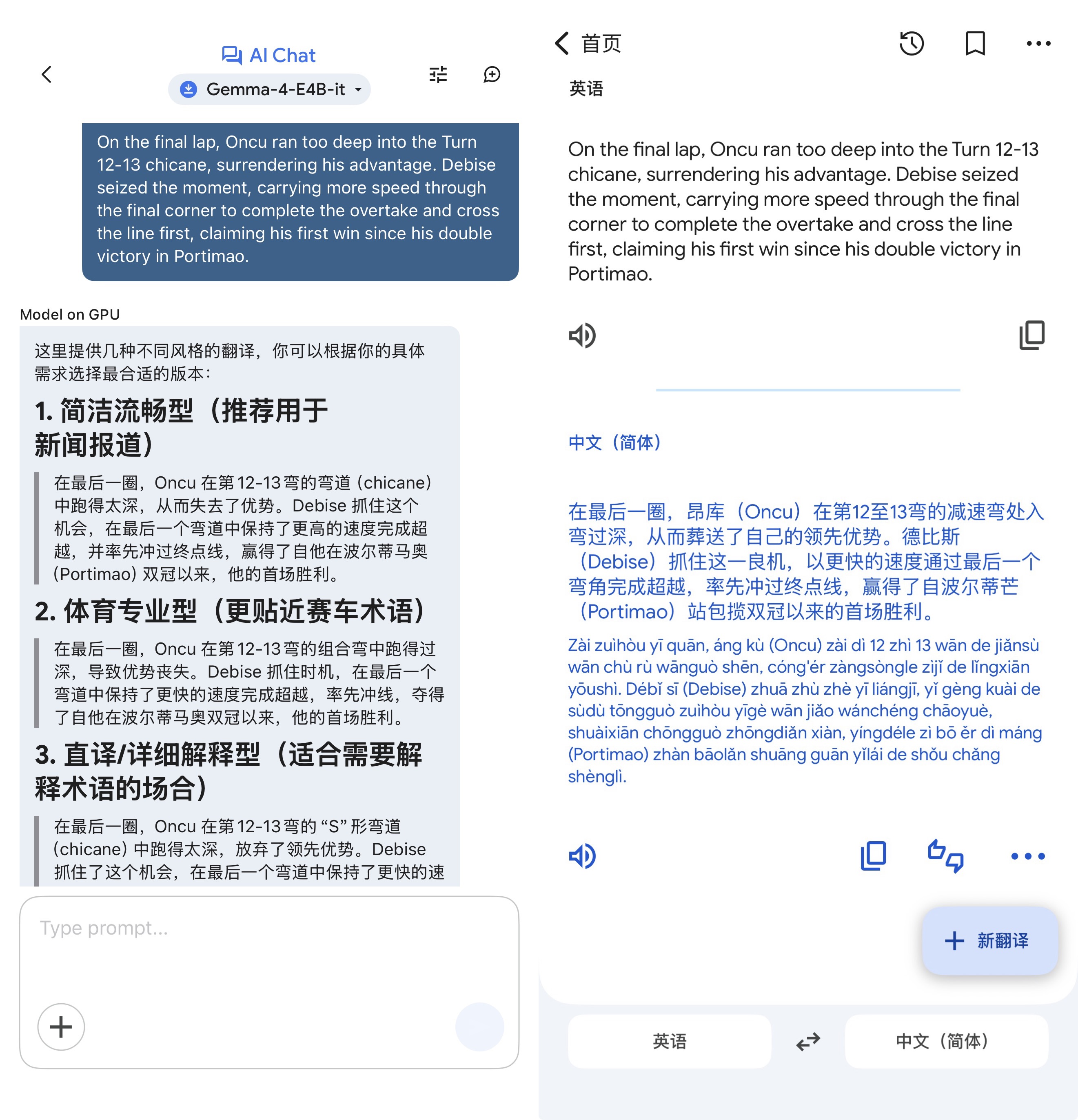
谷歌端侧模型和联网翻译工具的翻译效果对比(图源:雷科技)
无独有偶,腾讯混元也在近日开源手机端离线翻译模型Hy-MT1.5-1.8B-1.25bit,把支持33种语言的翻译大模型压缩至440MB,用户免费下载之后,可在手机直接运行,无需联网,官方称其翻译效果「比肩」商用翻译模型。
Gemma 4:端侧模型迈出的「不完美」第一步
最近几个月,各家的云端大模型迭代飞快,参数量和智能化比拼也来到新阶段。相比之下,不是新概念的端侧模型,也在努力前行,力求早日真正落地结果。
在体验一段时间后,雷科技(ID:leitech)的最大感受是,谷歌Gemma 4的推出,标志着端侧模型落地移动终端设备迈出的那「不完美」的第一步。
至于目前能力水平的端侧模型,推荐的人群有两大类:
1.天天都要查询古今中外大量信息的「百科向」用户,目前的端侧模型可以在一些领域更快、更直接、更定向地给出你想要的一个「初始版本」答案。
2.手机上装了大量离线app的「工具向」用户,目前的端侧模型可以在翻译、计算器、简单解题和测试训练,以及相对专业领域的基础信息科普咨询等工具应用领域有较好的表现。
当然,你想尝鲜,或者说见证端侧模型的一路成长,也可以下载体验。
对于iPhone用户,苹果即便在未来推出自家的端侧模型产品,大概率也就是谷歌Gemma端侧模型后续可以实现的程度。可以期待的「增量」或「加强」技能,主要也就端侧模型对于手机各项操作指令的「完美联动」和「无缝接入」。
图源:谷歌
需要指出的是,谷歌Gemma 4端侧模型的回答和响应速度,与你手机的运行内存和算力水平有着莫大关系。
iPhone用户,建议运存8GB起步,推荐12GB;安卓用户,建议运存12GB起步,推荐16GB。这样的配置,可以体验目前端侧模型的最佳运行表现。
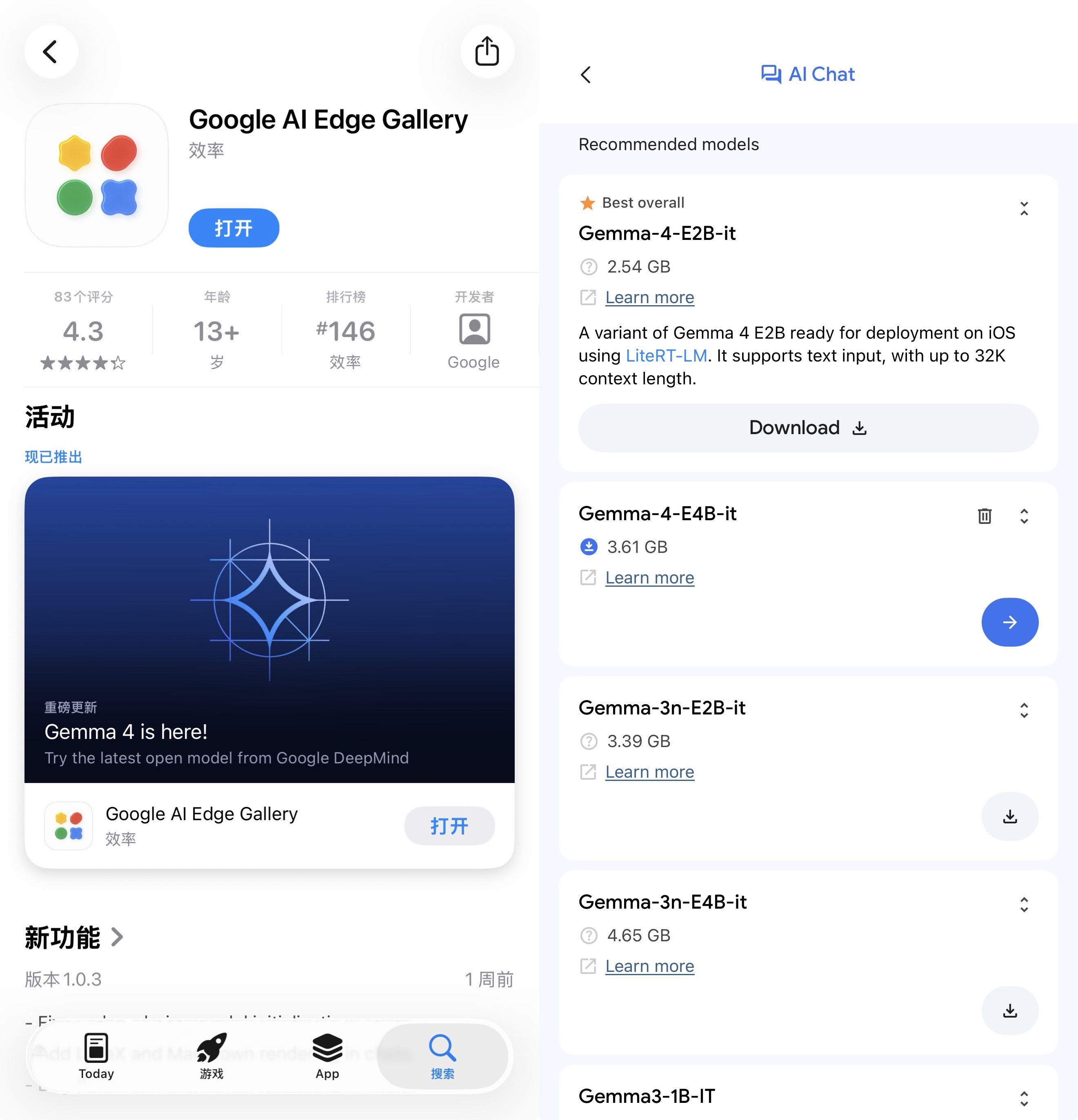
至于如何在手机上下载谷歌Gemma 4端侧模型,步骤极其简单,所有国内用户均可体验:
先在国区App Store或安卓应用商店下载配套的App,即Google AI Edge Gallery;其后可在App中对谷歌相关端侧模型直接进行本地部署(下载)和使用体验。
图源:雷科技
端侧模型,成了谷歌面向中国内地用户完全开放下载、并可直接使用的大模型产品。
而这似乎也预示着谷歌端侧模型(注:经过审查和备案后),未来有可能全面部署乃至预装到更多国产终端硬件设备,包括小型物联网终端设备等。
在这方面,谷歌已经在发力。Gemma 4模型支持业界通行的Apache 2.0许可,这意味着开发者可以更加自由地使用、修改和分发该模型,消除了以往商业化应用中的各项顾虑。
而通过与谷歌Pixel硬件团队以及高通、联发科等移动终端芯片平台企业合作,谷歌试图让Gemma 4端侧模型可以在更多安卓移动设备(尤其非高运存设备)上实现真正的「近乎零延迟」使用体验。
图源:雷科技摄制
可以想象,伴随未来旗舰手机(包括iPhone)运行内存全面迈入16GB阶段,「小模型」更多、更强、更高效的技能表现(尤其是与智能体的更成熟联动),以及更大的本地知识库信息储备量,端侧模型也将给用户带来全方位的加强版体验。
这一天,已经为时不远了。





