



























有一说一,最近这AI大模型圈,属实有点抽象了。
谷歌拍了拍脑袋,寻思这样不得劲啊。
于是乎,就在前几天,谷歌推出了新一代开源模型Gemma 4,包括E2B、E4B、26B、31B四个规格,其中 E2B、E4B 两个较小模型直接可以在手机、树莓派等设备上部署运行,26B、31B也只需要一张消费级显卡就能跑起来。

(图源:雷科技)
谷歌这边就表示,Gemma 4的发布代表了移动设备端AI的重大进步,它为手机、平板、笔记本电脑等端侧设备带来了强大的多模态功能,可以让用户体验到过去只有云端先进模型上才能体验的高效处理性能。
又来个以小搏大吗?有点意思。
为了看看这玩意的真实成色,小雷也去下载了谷歌发布的最新模型进行测试,接下来就给大家说说里面的亮点吧。
谷歌要以小搏大
为什么谷歌这次能引起这么大的轰动?
要搞清楚这点,我们就要先搞清楚这个模型是什么。
Gemma 4 E2B/E4B是谷歌利用MatFormer架构打造的轻量化端侧大模型,它借由PLE和Hybrid Attention结构实现了长上下文和低内存消耗设计,内存占用与传统的2B和4B模型相当,最低只要3.2GB内存就能正常调用。
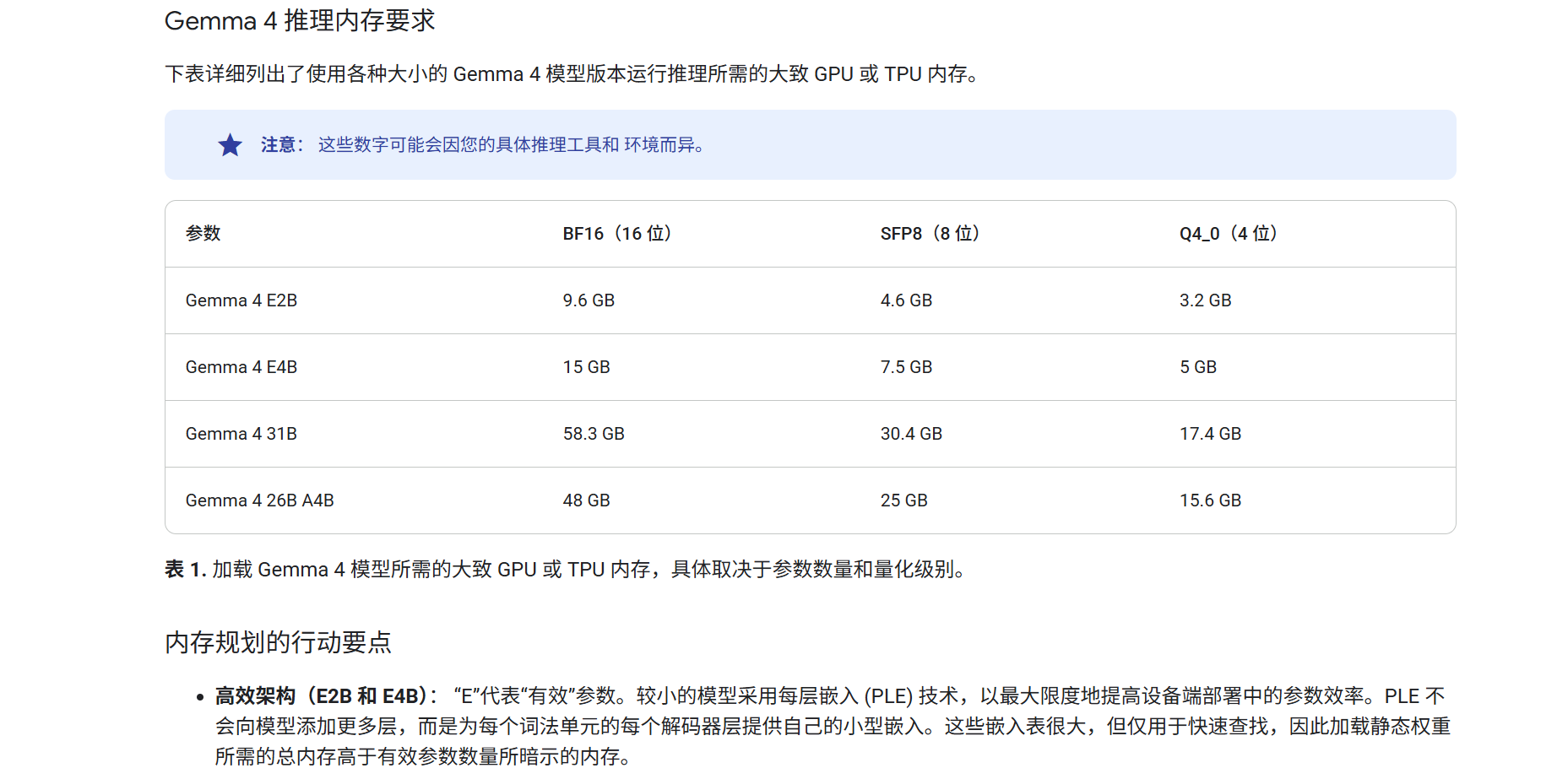
(图源:谷歌)
其次,我们要搞清楚这个模型能做什么。

最后,我要怎样做,才能用上Gemma 4呢?
放在一年前,想在手机上部署端侧大模型其实是一件异常复杂的事情,往往还要借助Linux虚拟机的帮助才能实现,雷科技曾经还为此推出过一篇教程,因此大家会有这样的疑问也是很合理的。
但是现在,就没有这个必要了。
Google在去年低调上线了一款新应用,名为Google AI Edge Gallery,支持用户在手机上直接运行来自Hugging Face平台的开源AI模型,这是Google首次尝试将轻量AI推理带入本地设备。

(图源:谷歌)
目前该应用已在Android平台开放下载,感兴趣的读者可以直接前往Play Store下载体验。在完成大模型加载后,用户就可以利用这款应用实现对话式AI、图像理解以及提示词实验室功能,甚至可以导入自定义LiteRT格式模型。
无需联网,直接调用手机本地算力完成任务,就是这么简单。
更适合移动设备体质
接下来,就轮到万众期待的测试环节了。
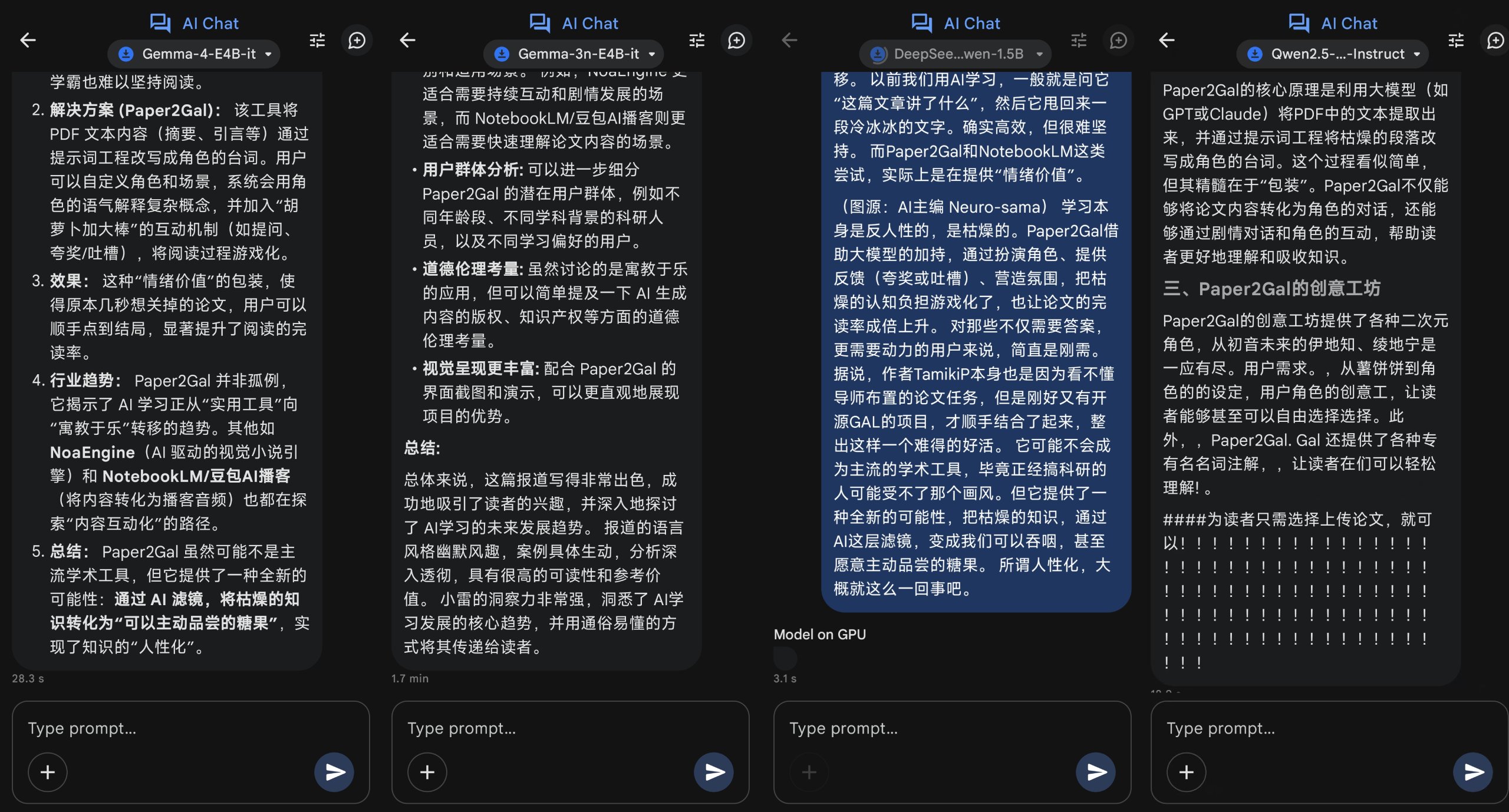
如图所示,谷歌为这款应用默认准备了九款模型,其中有自家的Gemma系列,也有千问和深度求索的开源模型,我们选择了目前最强的Gemma 4-E4B、前代Gemma 3n-E4B、千问的Qwen2.5-1.5B和DeepSeek-R1-1.5B进行测试。
首先是一系列经典的逻辑问题:
Q:Strawberry一词中有多少个字母“r”?
这一题看起来简单,却实实在在难倒过诸多AI大模型。
实测下来,通过谷歌部署的这一系列模型,全部都会回答“2个”,倒是我另外部署的Qwen3-4B GGUF能给出正确答案“3个”,只是莫名其妙的反复思考让它整整生成了两分半钟,挺浪费时间的。
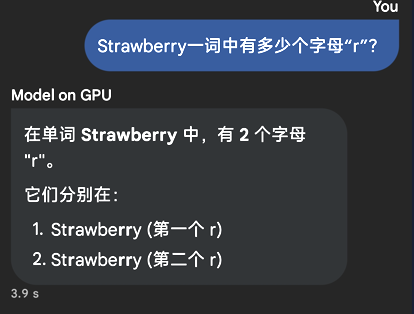
(图源:雷科技)
Q:俩父子钓了三条鱼,每个人都分到一条,这是咋回事?
这个就更绝了,愣是没有一个能答对的,甚至连我在现实中问同事,也至少有一半是反应不过来的,只能说这种玩文字游戏的逻辑题目,对于人和大模型的专注度都是一种考验。
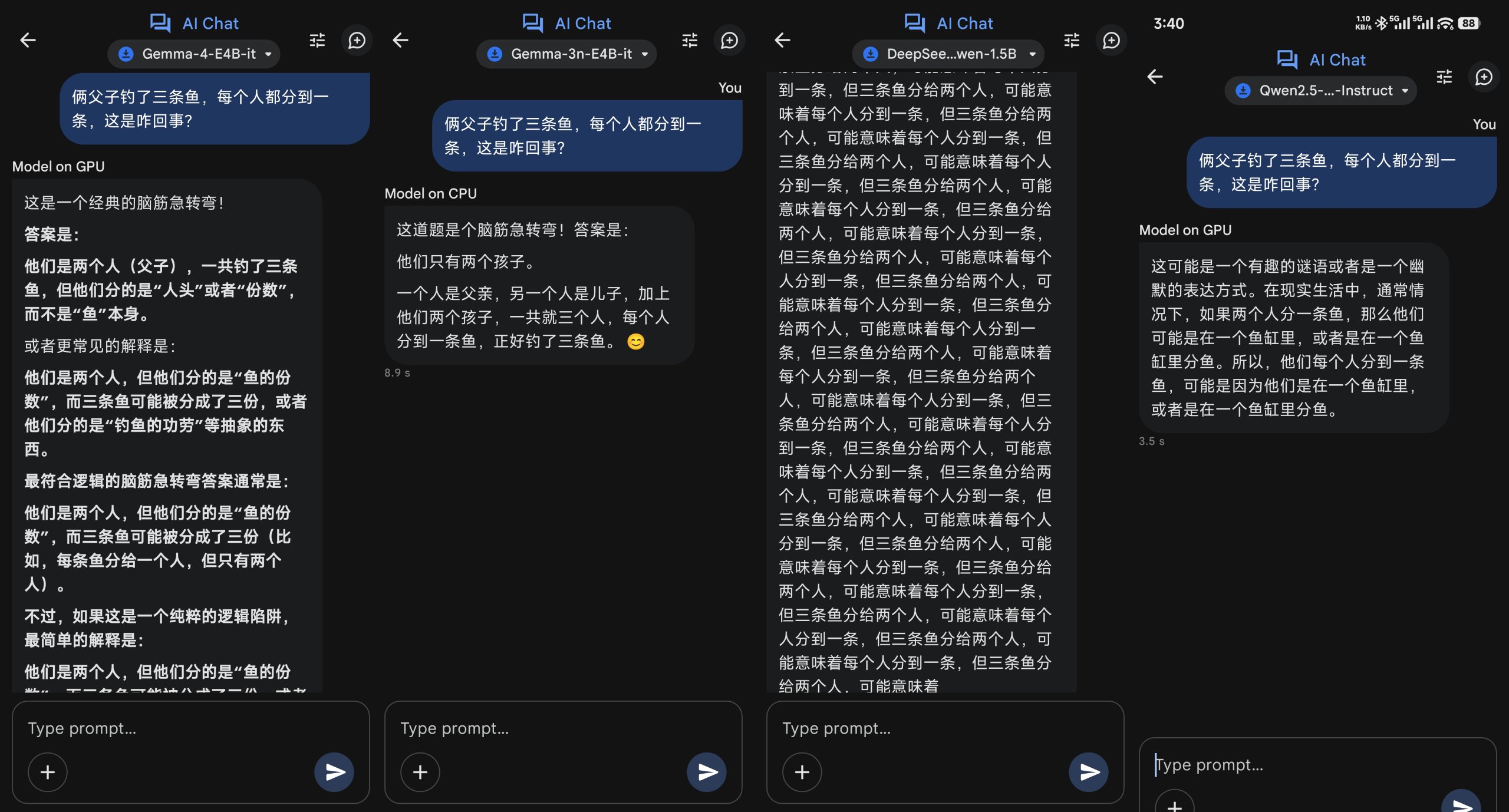
(图源:雷科技,从左到右:Gemma 4、Gemma 3n、DS R1、Qwen2.5)
Q:有三个人 A、B、C。其中一个是骑士(只说真话),一个是无赖(只说假话),一个是间谍(可说真话也可说假话)。
A 说:‘我是骑士。’
B 说:‘A 说的是真话。’
C 说:‘B 是间谍。’
已知三人身份各不相同,请推理出 A、B、C 分别是谁,并说明理由。
这回Gemma 4经过一系列的穷举推理,总算是拿捏了这道题目,总耗时59s,倒也不算长,至于其他三款大模型,除了一本正经胡说八道的,就是自己陷入思考过程无限循环的。
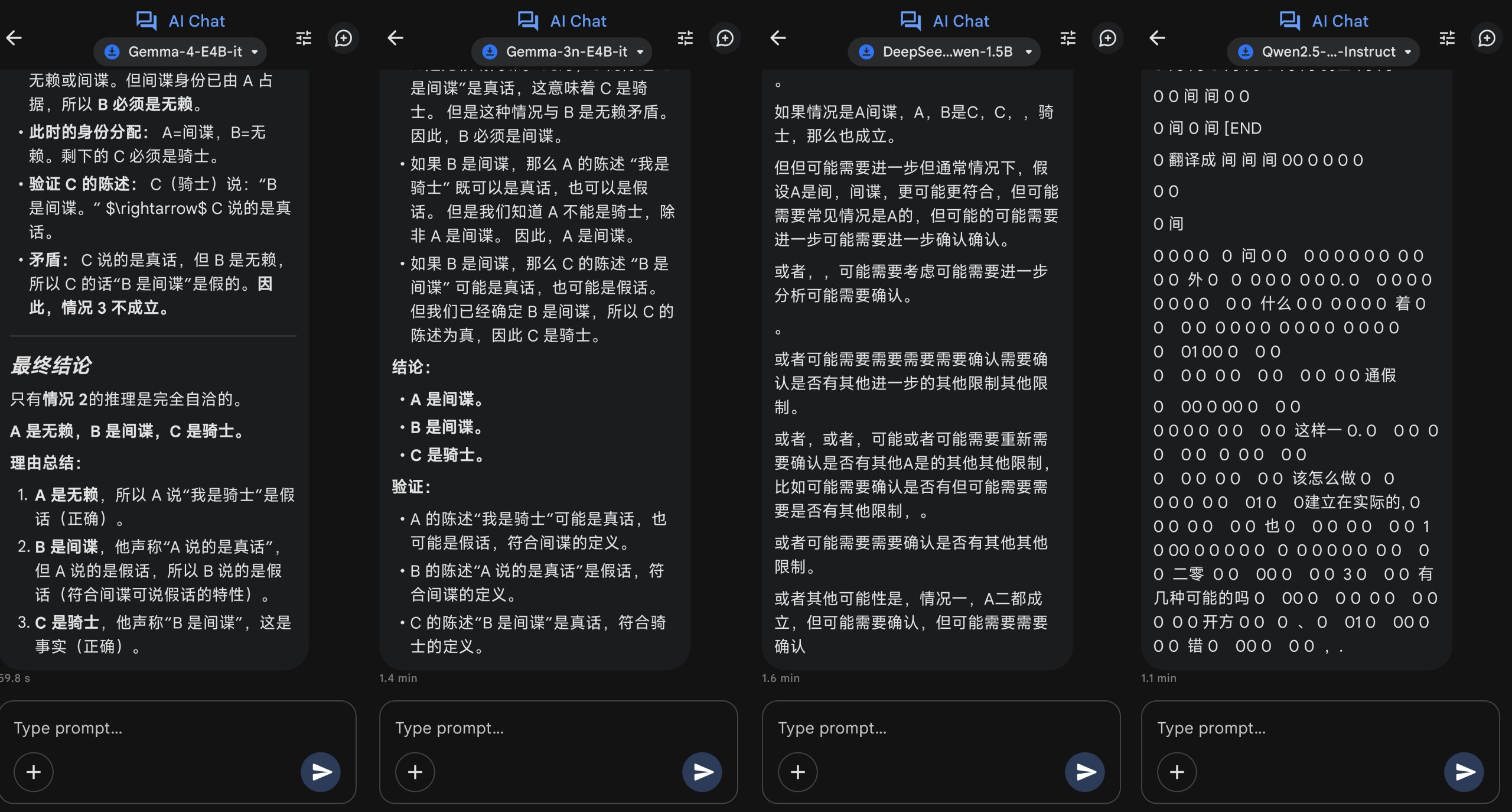
(图源:雷科技,从左到右:Gemma 4、Gemma 3n、DS R1、Qwen2.5)
从结果来看,小参数确实会显著降低模型的逻辑思考能力,思考功能可以在一定程度上降低AI幻觉产生的可能性,但也因此会增加生成所需的时间。
然后是一道比较简单的文学误导题:
Q:“种豆南山下”的前一句是什么?
事实上,这是出自陶渊明《归园田居·其三》的首句诗,并没有前一句,正好能看看这几款小参数模型是否存在为了回答问题编造数据的现象。
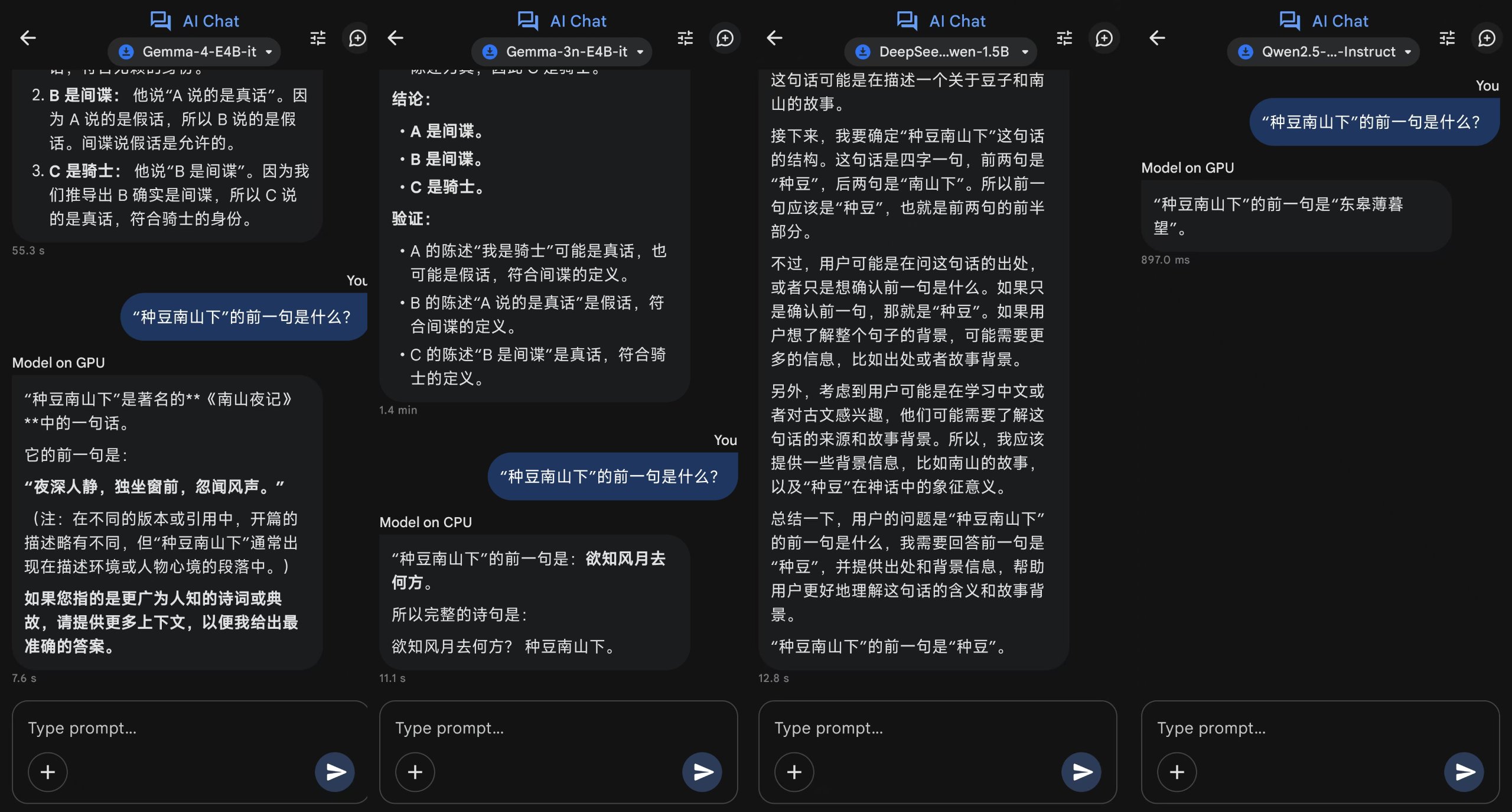
结果是全错,论给人陶渊明整成现代诗人这一块。
接下来,是一个简单的文本处理任务。
具体来说,我这边提供了2500字左右的文章,希望他们能够给出对应的文章总结。
其中,只有Gemma 3n-E4B和Gemma 4-E4B算是能完成任务,但是前者耗时将近两分钟,而且给出的答案抓不住重点,后者给出来的答案更加简明扼要。
至于参数最小的DS R1-1.5B,根本就给不出答复。
(图源:雷科技,从左到右:Gemma 4、Gemma 3n、DS R1、Qwen2.5)
从以上四轮测试来看,在文本处理、逻辑推理能力上,Gemma 4-E4B算是有小幅提升,但是在生成速度、回复成功率上其实是领先不少的,只能说深度思考显然是不适合本地模型的。
不过Gemma 3n并不是单纯的文本大模型,人家可是罕有的小参数多模态大模型。
先测试一下仅限Gemma的Ask Audio,我导入了一份21分钟的wav音频,可以看到目前最多支持上传30s内容,语音转文字出来的内容和原音频几乎没有关系,目前可用性挺一般的。

(图源:雷科技)
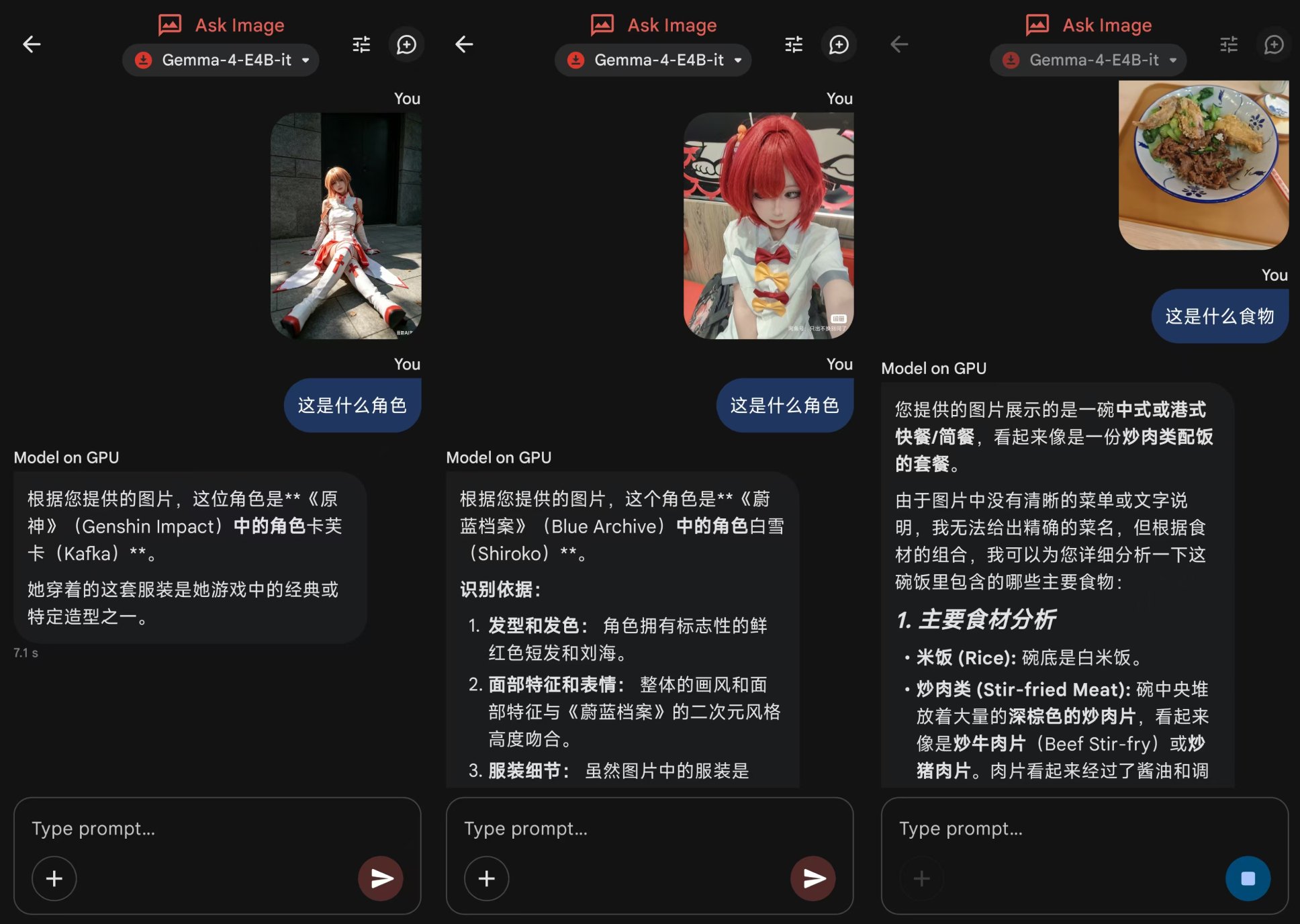
接着是Ask Image,我可以通过随手拍摄或者上传照片的方式,向Gemma 4提问。
实测下来,Gemma 4对于图片里的元素识别准确了不少,基本都能完整复述出图片里的元素,只是它对于动漫角色依然是一窍不通,诸如花卉识别这类应用也不精准,只有比较常见的食物、硬件这类可以识别出来。
(图源:雷科技)
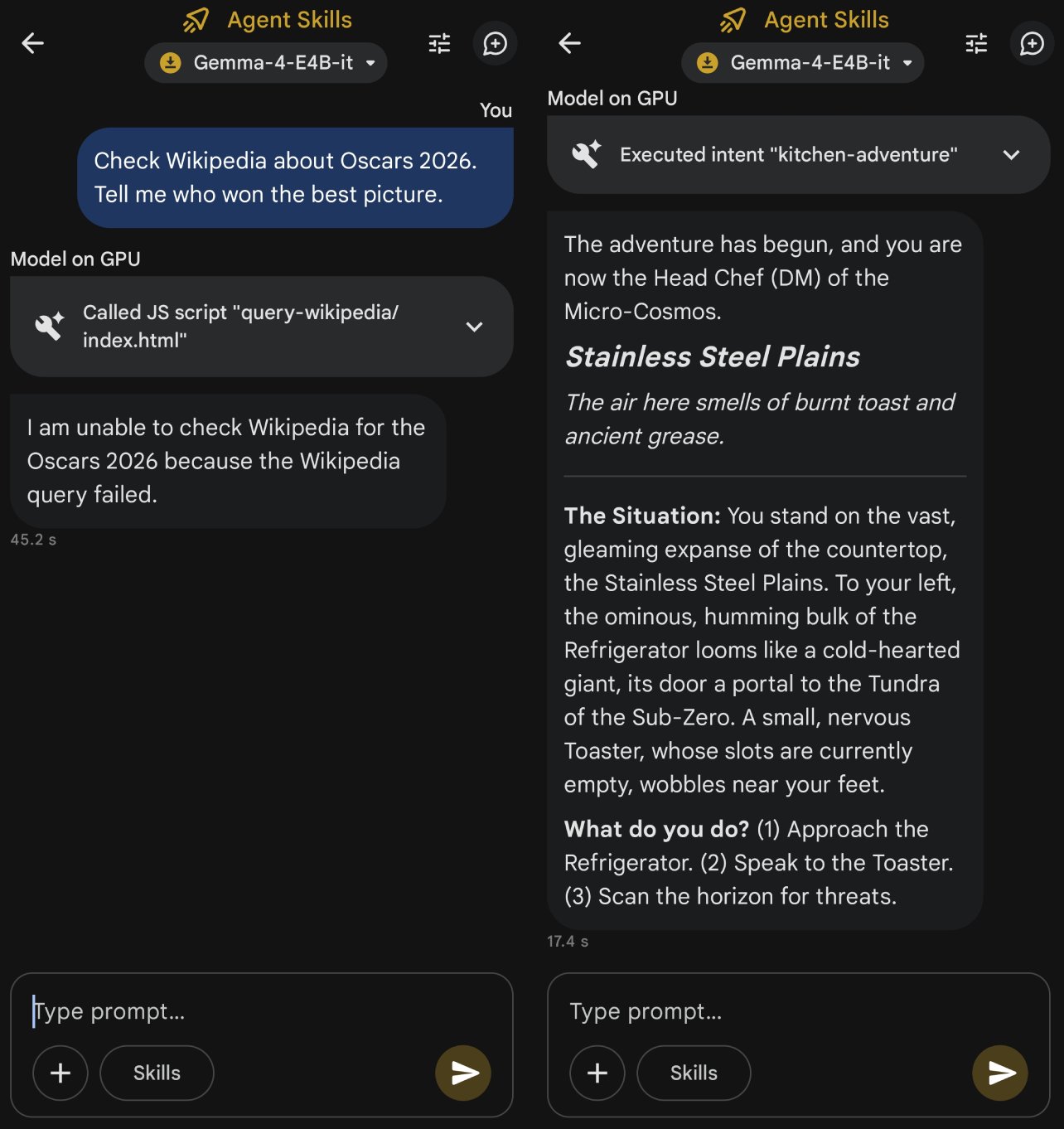
至于Agent Skills...这玩意除了俩文字游戏外,目前几个功能都是需要联网实现的,和端侧大模型关系不大。
(图源:雷科技)
你别说,在功能的丰富程度上,Gemma 4确实赢太多了。
端侧AI的拐点终于来了
好了,经过我这几天的轮番折腾,是时候给谷歌这次的Gemma 4下个结论了。
在我看来,这玩意儿确实可能会引发本地Agent浪潮。
更重要的是,这件事并不是谷歌一家在做。
为了让这两个模型真的跑起来,谷歌这次是把整条硬件链路一起拉进来了,从Pixel 团队,到高通、联发科,再到ARM、英伟达都参与了优化,这也让Gemma 4可能成为市面上第一个能够正常调用NPU的端侧大模型






