



























文章开始之前,给大家听一下我们用AI做的一首《雷科技之歌》。
初代《中国最强音》总冠军曾一鸣在用真人演唱迎战AI作品《泪海》后,曾公开给出一个判断:
“再过一段日子,各大平台的排行榜,都会被AI音乐屠榜。”
这个判断,比想象中来得更早。最近在网上冲浪时,相信不少人都刷过这样的内容:大量“AI周杰伦”、“AI孙燕姿”等,翻唱着歌手本人从未演绎过的曲目,粉丝们无不惊呼。
说到AI歌曲,就不得不由酷狗阿波罗声音实验室独立研发的AI虚拟歌手“大头针”,目前已累计上线近2000首翻唱作品,单月最高听众达2517万。在流媒体的数据对标上,这一量级已经逼近了周杰伦同期的月听众规模。
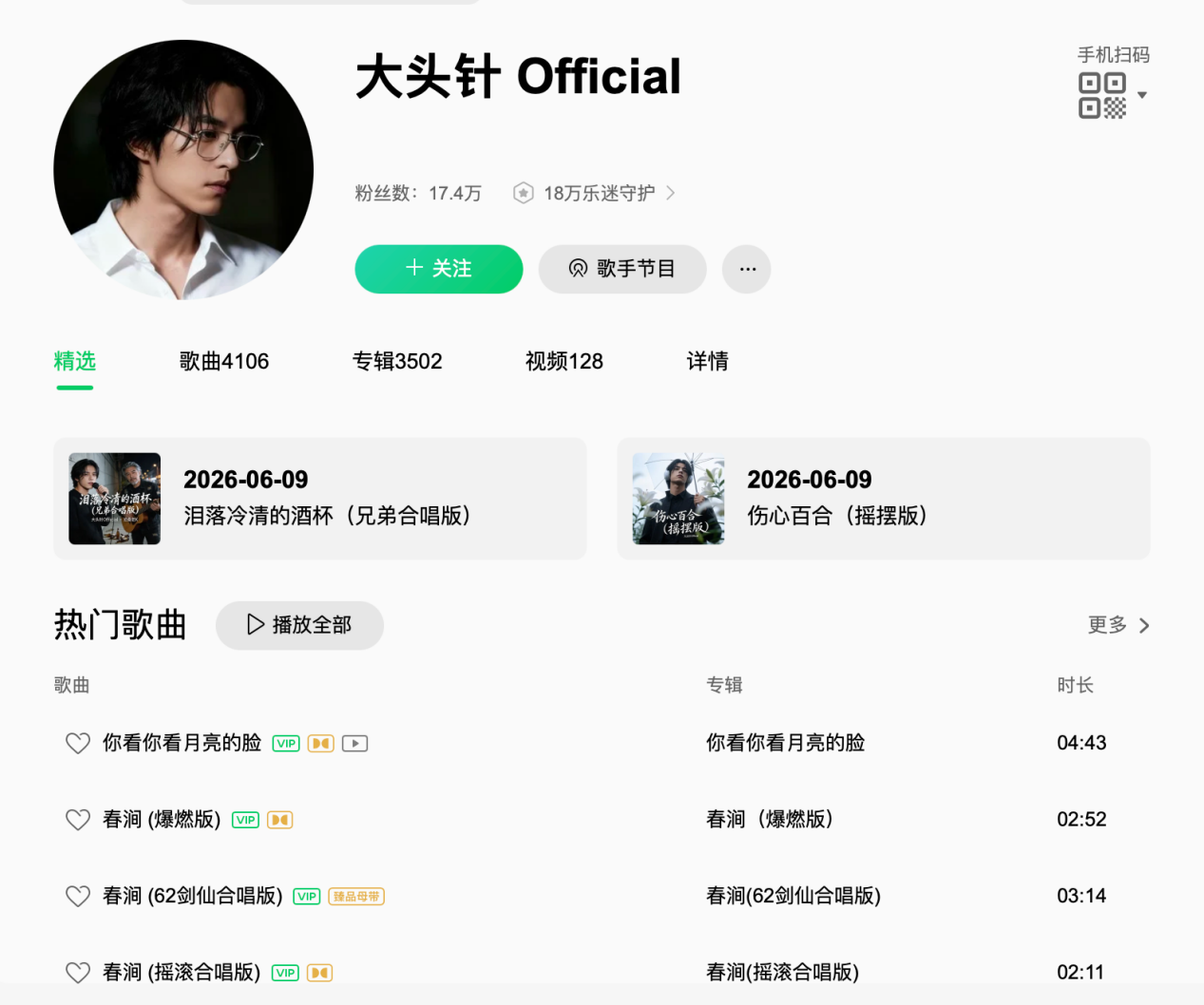
图源:QQ音乐
与此同时,AI虚拟歌手正在从“纯音频Token”向着具备完整人格特质的“虚拟偶像”演进。今年1月,在北京亦庄拿到全国首个虚拟偶像身份证的“Yuri”,不仅在歌曲平台上持续输出,更深度渗透进公共文化活动中。在出道曲《Surreal》发布后,鸣潮、岚图汽车等品牌方的商业合作接踵而至,虚拟声线商业变现上确实有可行性。

图源:岚图汽车
这种现象正在全球蔓延。6月6日,特朗普发布AI单曲《人人都爱特朗普》,歌词写道:“不管我走到哪儿 人人都爱特朗普,来到墨西哥,他们喜欢特朗普;去到意大利,他们喜欢特朗普……”。
秉持“绝知此事要躬行”的精神,雷科技(ID:leitech)决定独自下场实测,尝试制作一首《雷科技之歌》,然而,在经历了长达数小时的重度死磕后,我们发现了AI音乐在底层机制上的硬伤。
AI写歌,其实是一个“聋子”在用数学作曲
作为当前的AI音乐顶流,Suno和Udio基本撑起了行业的半壁江山。在实测开始前,我推测AI写歌的逻辑与人类相似,是基于旋律和节奏的实时反馈进行增量修改。但当我真正尝试生成《雷科技之歌》时,首轮测试就遭遇了跨模态对齐的逻辑翻车。
图源:Suno.cn
问题出在歌词的解读上,为了全面测试AI对垂直专有名词和中文多字句的驾驭能力,我通过GPT生成了一版歌词,这个歌词里面包含了大量的多字排比句,以及雷科技旗下的垂直IP矩阵,比如“微信、抖音、B站/ 看小雷聊数码把硬件都拆穿 / 看软硬结合的AI 怎么把体验填满”等等。
然而,算法吐出来的成品完全暴露了它对垂直名词的理解缺失。AI将“小雷聊数码”进行了生硬的截断,在“小雷”后面出现了无意义的断气,随即将“聊数码把硬件”连在一起黏糊糊地唱了出来。这种不符合基本乐理和发音常识的低级错位,在随后的数十次抽卡中高频出现。
图源:Suno.cn
可见,AI音乐并没有听觉,它本质上是在用视觉大模型的逻辑去画一张频谱图。
从底层架构来看,Suno或Udio的第一步是利用声学编解码器(Neural Audio Codecs),将连续的音频信号切碎成每秒数百个微小的音频切片,并将其转化为离散的代码,也就是音频Token。
在模型内部,副歌的情绪和独白的平铺没有高低之分,它们只是两串不同概率分布的矩阵数据。
这依然是Transformer架构最擅长的概率预测游戏。大模型计算的是在当前的上下文环境下,前一秒的数字编码后面接哪一个音频Token的概率最高。当它通过自回归模型算出一串数字序列后,再利用扩散模型进行去噪拟真,最终输出音轨。
这种依赖统计学概率的拼图逻辑,导致它建立的只是“字”与“发音编码”的强绑定。它不具备真正的旋律逻辑,更不懂得中文词组的语境语义,因此在处理稍微复杂的垂直词组时,极易出现错位断句和转音崩塌。
AI没有风格,它只有大数据的“刻板印象”
在摸清了音频Token化的底层机制后,我开始了第二轮测试。在歌词的第三段,时间指针被拉到了2026年,里面的细节更加具象且充满现场感:“飞过太平洋,奔赴不眠的内华达 / CES的展会现场,没有大雪、只有风沙”。
为了衬托这种“创始人带队奔赴前线”的极客感,我试图让AI呈现出一种带有前沿探索感、冷峻且宏大的科技电子流行风。但算法很快展现出了大数据二道贩子的局限。
三十秒后,软件吐出来的音频具有极强的夜店土嗨感。大模型用一种缺乏情感起伏的DJ腔,机械地高喊着“没有大雪、只有风沙”,配上劣质的重低音,活生生把一个科技报道团奔赴内华达沙漠的壮丽现场,唱成了土味夜店的喊麦神曲。
图源:Suno.cn
这暴露了AI写歌的另一个技术瓶颈:它不具备审美和风格的创新能力,它只有对大数据的刻板印象。
人类的风格创新往往来自于对既有规则的打破,而AI的算法逻辑恰恰相反,它永远倾向于选择全互联网大数据统计下来概率最高、最稳妥的陈词滥调。AI在抓取了全网被标记为“科技”的音乐样本后,发现其中高频出现的是廉价的电子合成器和重低音,于是它便将这些大数据的平均值进行打包和放大。
当遇到“内华达、CES、风沙”这种在传统音乐库里几乎找不到对应模版的词汇时,它的算法机制就会自动向下兼容,向着最平庸、最安全的“夜店风”坠落。
由于它是不可控的黑盒逻辑,在这个由概率支配的系统里,你只要微调一处提示词,就会彻底塌陷并重新洗牌。
图源:Suno.cn
为了强行纠正它,我只能放弃人类语言的宏观描述,改用纯粹的结构化思维进行对赌:将歌词手动切碎,使用方括号标记极其严格的结构标签,在“内华达”和“CES”之间手动加入标点符号强行纠正断句,并利用“垫音(Extend)”功能,截取听起来勉强及格的前30秒,再进行局部的增量续写。
在消耗了上百个平台积分、在海量无效音频中进行人工筛选后,这首《雷科技之歌》终于被拼凑了出来。
坦白讲,扩散模型赋予了最终成品极高的技术完成度,无论是高逼真的泛音还是均衡的混响,都具备了工业级的外壳。但这并非技术理解了音乐,而是高效率重组流水线的结果。
AI并没有消灭音乐的艺术,它只是重构了音乐的工业基础。
它能快速清洗掉低端市场的重复制作者,但由于受限于统计学平均值的底层逻辑,它很难越过概率去爆发属于人类创作者的神来之笔。
成本几乎可忽略,AI歌曲成营销新手段
坦白来说,以上对于AI写歌的吐槽有点吹毛求疵,当我们把目光从狭隘的艺术层面移开,站在行业和品牌营销的角度来看,AI音乐在微观细节上的这些硬伤,在商业效率面前其实并不重要。
《雷科技之歌》包括歌曲制作+MV生成,大概花了我56块会员费(额度还没用完),这点钱在营销层面,几乎可以忽略不计。
如果没有AI,传统的品牌营销曲是一件高边际成本的消费品。从邀请词曲创作者、寻找歌手、再到进棚录音及后期混音,一首合格的品牌主题曲往往需要数十万的预算以及数月的制作周期。而AI音乐的出现,直接将生产成本与时间周期砸到了传统行业的视线死死角之外。
这种几乎为零的试错成本,让“即时内容营销”真正具备了实操性。
例如特朗普的AI单曲,很恶搞,但从商业逻辑来看,它是一次极度精准的政治与情绪营销。通过AI工具在几分钟内就能将政治口号、时事热梗,以极低的成本将严肃议题转化为流行符号。
图源:X
这种玩法同样可以复制到商业品牌上,比如,中午互联网刚爆出一个热梗,运营下午就能利用AI做出一首魔性洗脑的歌曲配合分发,这种快速响应的能力直接拉高了内容产出的效率。
还有一种对用户的精细化运营。比如,新能源汽车在车主提车时,系统可以提取用户的兴趣标签,现场在数秒内自动定制一首包含车主名字的专属提车曲,直接推送到车机上。
一些平台在进行年终盘点时,也能为海量用户每个人生成一首专属的生活足迹单曲。这种玩法在传统音乐工业时代是无法计算投入产出比的,而现在它变成了极低成本的情绪价值。
写在最后
在《雷科技之歌》最终拼凑完成时,我有种“总算凑出来了”的感觉,但这种如释重负,本身就说明问题,AI能帮你交差,但交不出惊喜。它擅长把大数据的平均值打包成安全牌,却写不出深夜灵感迸发时那句让人起鸡皮疙瘩的歌词。
未来的音乐创作,大概率会走向分层:神来之笔依然属于人类,而标准化、即时响应的内容生产,交给算法就好。音乐不会死,只是创作的门槛和权力分配,正在被重新洗牌。





