



























北京时间 6 月 10 日凌晨,Anthropic 在没有任何预热的情况下,放出了旗下最强大模型 Claude Fable 5/Mythos 5,前者面向公众开放,后者继续留在 Project Glasswing 这样的受控项目里。
Fable翻译为“寓言”,如果只看名字,Fable 5 像是 Claude 产品线里又一个新成员。但按照 Anthropic 自己的说法,Fable 5 属于 Mythos-class 模型,是他们终于敢拿出来给普通开发者和企业使用的公开版 Mythos,而Mythos翻译为“神话”。

(图源:Anthropic )
为什么说「终于敢拿出来」?Mythos 这个名字,在过去两个月里几乎等同于「危险」。今年 4 月,Anthropic 发布 Project Glasswing,把 Claude Mythos Preview 交给 AWS、Apple、Cisco、CrowdStrike、Google、微软、NVIDIA、Linux Foundation、Palo Alto Networks 等少数安全伙伴,用于寻找和修补关键软件漏洞。那时 Anthropic 的态度很明确,Mythos Preview 不做广泛开放,原因很简单,它的网络安全能力已经强到可能被滥用。

(图源:Anthropic )
官方直言,Mythos 发现过大量高危漏洞,甚至包括主要操作系统、浏览器和关键软件里长期没人发现的问题。放在防守者手里,它是安全工具;放在攻击者手里,它可能变成下一代自动化漏洞挖掘机。于是,Mythos 被关进了 Project Glasswing。
直至刚刚,Anthropic 才终于把这个模型放了出来。Anthropic 给 Fable 5 加上安全分类器,高风险请求可能拒答,也可能回退到 Opus 4.8。简单来说,他们给一个曾经不能直接放出来的模型套上护栏,然后把它推向市场。雷科技AGI(ID:leikejiagi)熬夜整理了关于这个模型的一些资料,希望对你有用。
A社再造模型「神话」,Fable 5成最强没有之一
Fable 5 的跑分看起来非常不讲武德。SWE-Bench Pro 上,它拿到 80.3%,高于 Mythos Preview 的 77.8%、Opus 4.8 的 69.2%、GPT 5.5 的 58.6%、Gemini 3.1 Pro 的 54.2%。如果只看这一项,它已经是第一梯队里最显眼的那个。
真正离谱的地方在 FrontierCode Diamond,这个评测更接近真实软件工程,它看的是模型能不能写出维护者愿意接受的代码。Fable 5 拿到 29.3%,Opus 4.8 只有 13.4%,GPT 5.5 只有 5.7%。这已经不是多赢几个百分点的问题,上一代 Claude 和主要对手都被拉开了距离。
过去很多 AI 编程模型会写代码,但工程质量常常不稳定,有些代码能跑,却很难维护;有些代码能过测试,放进真实项目还是会出问题。FrontierCode 的残酷就在这里,它关心模型有没有工程品味,能不能在复杂代码库里做长期任务。Fable 5 在这里大幅领先 Opus 4.8,说明 Anthropic 这次真正升级的是 agent 编码的灵魂。

(图源:Anthropic )
在Terminal-Bench 2.1 上,Fable 5 是 88.0%,Opus 4.8 是 82.7%,GPT 5.5 Codex CLI 是 83.4%,Gemini CLI 是 70.7%。这意味着在终端环境里执行任务、读报错、改代码、继续推进,Fable 5 已经压过了 OpenAI 的 Codex CLI 组合。
跑分不是那么重要,Fable 5真正吓人之处在于,它已经像一个能在工程现场干活的模型。你把任务扔给它,它能读项目、拆任务、调工具、修错误、继续跑。Anthropic 发布稿里提到,Stripe 用 Fable 5 在 5000 万行 Ruby 代码库里做迁移,把原本一个团队两个月的工作压缩到一天。这种案例即便带着营销成分,也挡不住 AI 编码正在从辅助写函数进入接管工程流程。
我们拿 DeepSeek V4-Pro Max 做个不太恰当的对照,其在 GPQA Diamond 上有 90.1%,LiveCodeBench 有 93.5%,SWE Verified 有 80.6%。这已经是开源阵营里非常能打的成绩,Qwen3.7-Max 在 GPQA、SWE Verified、Terminal-Bench 等方向也打出了存在感。对于熟悉 DeepSeek 的读者来说,这意味着国产和开源模型并不弱,很多传统强基准已经接近最强闭源模型。

(图源:雷科技制图 )
但到了更接近真实工程和长任务执行的指标,Fable 5 的压迫感突然变强。SWE-Bench Pro 上,Fable 5 是 80.3%;DeepSeek V4-Pro Max 官方表里的 SWE Pro 是 55.4%;HLE with tools 上,Fable 5 是 64.5%,DeepSeek V4-Pro Max 是 48.2%;Terminal-Bench 虽然版本不完全一致,Fable 5 在 2.1 上拿到 88.0%,DeepSeek V4-Pro Max 在 2.0 上是 67.9%。Fable 5全都断崖式领先。
这些数字其实不一定完全能说明问题,但方向很清楚,DeepSeek 强在性价比、开源和一批传统能力指标,Fable 5 强在最贵、最难卖出高价的任务,尤其是长任务 agent、复杂工程、工具协同和真实代码库处理。
视觉和空间推理也在猛涨,比如GDP.pdf 这类知识工作视觉任务里,Fable 5 是 29.8%,高于 Opus 4.8、GPT 5.5 和 Gemini 3.1 Pro。Blueprint-Bench 2 上,Fable 5 是 38.6%,略高于 GPT 5.5 的 36.2%,远高于 Opus 4.8 的 14.5%。这解释了为什么 Anthropic 强调 Fable 5 能从截图重建网页应用、从科学图表里提取精确数字。
到了 Fable 5 这里,处理图片、视频等多模态更像是把屏幕、图表、界面和代码连成一个完整任务链。它看懂一个页面时,有机会直接复刻页面;它读懂一张图时,也能把图里的结构变成下一步操作。
Fable 5让 Anthropic 不敢完全放开的则是网络安全和生物能力。ExploitBench Cap% 上,Fable 5 是 78.0%,Mythos Preview 是 69.0%,Opus 4.8 只有 40.0%,GPT 5.5 是 34.0%,这个差距非常夸张。放在安全防御里,它意味着模型能帮企业和开源维护者更快发现漏洞;放在错误的人手里,它也会继续拉低攻击门槛。
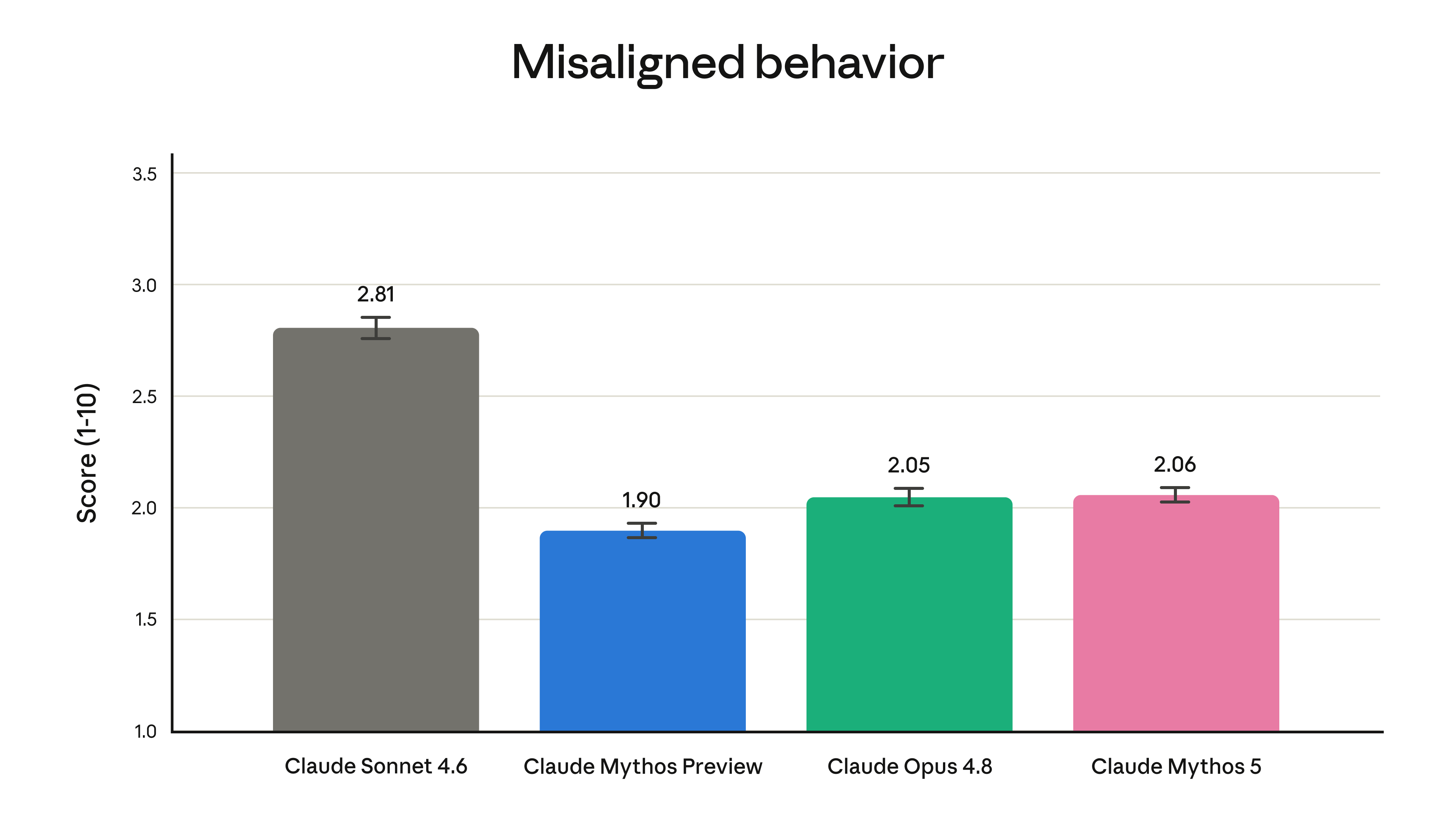
(图源:Anthropic )
BioMysteryBench hard 上,Fable 5 是 46.1%,高于 Mythos Preview 的 29.6% 和 Opus 4.8 的 40.0%。Anthropic 还提到 Mythos 5 在药物设计相关流程中带来约 10 倍加速,分子生物学假设在盲测中获得研究者偏好的比例约 80%。这听起来像科研利好,也足够让监管者紧张。
所以,Fable 5 的强不只来自「更聪明」。它强在长任务,强在工程交付,强在视觉理解,强在安全和科研这些高价值也高风险的专业场景。某种意义上,它就是 Anthropic 目前能够被大众公开使用的最强大模型,没有之一。
当所有人在降价时,Anthropic把AI卖成奢侈品
Fable 5 再强,也绕不开一个现实问题,它贵得离谱。官方价格是每百万输入 token 10 美元,每百万输出 token 50 美元,作为对比,Claude Opus 4.8 是 5 美元输入、25 美元输出,Fable 5 直接翻倍。
更尴尬的是,它发布的时间点,正好撞上大模型打价格战。DeepSeek V4-Pro 当前 API 价格已经来到每百万输入 token 0.435 美元、输出 0.87 美元,V4-Flash 更低,输入 0.14 美元、输出 0.28 美元。
小米 MiMo-V2.5 系列也在 5 月底完成永久降价,海外版 MiMo-V2.5-Pro 同样是输入 0.435 美元、输出 0.87 美元,官方还强调最高降幅可达 99%。Google 这边,Gemini API 仍有大量低价模型可选,Gemini 3.5 Flash 是输入 1.5 美元、输出 9 美元;订阅层面,Google 还把 AI Ultra 顶配套餐从 250 美元降到 200 美元。

(图源:雷科技制图)
也就是说,行业一边在把 1M 上下文、agent 编码、多模态能力往低价区间里压,Anthropic 一边把 Fable 5 定在输入 10 美元、输出 50 美元。和 DeepSeek V4-Pro、MiMo-V2.5-Pro 相比,Fable 5 的输入价格大约高 23 倍,输出价格大约高 57 倍。即便对比 Gemini 3.5 Flash,也贵出数倍。这个价格足以劝退大量普通开发者。
但 Anthropic 的算盘也很清楚,它不想让 Fable 5 去做便宜模型能做的事情。日常问答、轻量写作、普通代码补全,当然没必要上 Fable 5。它卖的是大型代码库迁移、长上下文文档分析、复杂企业流程、网络安全防御、科研假设生成这些高价值任务里的时间。用最扎心的话来说就是,假如你觉得你的时间更值钱,那就上 Fable 5 吧。
如果一个模型真的能把两个月工程压成一天,它当然敢贵。但企业采购时会先算一笔账,比如模型价格只是第一层,数据保留是第二层,合规是第三层。Fable 5 被列为 Covered Model,在 Claude API 上要求 30 天数据保留,不支持 zero data retention(普通数据保留),对金融、医疗、法律、核心研发团队来说,这不是小事。

(图源:Anthropic )
还有,Fable 5 还有一个麻烦点,它在网络安全、生物等敏感问题上会自动触发安全审查,有些问题它会直接拒绝回答,有些问题会改用能力弱一点的 Opus 4.8 来回答。对普通用户来说,这可能只是「问着问着被拒了」,但对企业来说,这会变成工程问题。
这就形成了一个非常有意思的两个阵营,DeepSeek、MiMo、Gemini 在证明,强模型会越来越便宜,越来越容易被开发者和企业大规模调用。Anthropic 则在证明,真正顶级、真正接近生产力核心的模型,反而可能越来越贵,越来越像奢侈品级基础设施。
但哪个阵营才会是真正的未来?谁都说不准。
Fable 5 压迫感太强,友商的日子都不好过了
Claude Fable 5 的发布,会让很多公司难受。OpenAI 会难受,因为 Anthropic 继续在 agent 编码和长任务上打出了存在感。Codex 周活已经超过 500 万,OpenAI 正在把 ChatGPT、Codex 和未来 AI researcher 变成工作入口,但 Fable 5 的出现提醒市场,Claude 在复杂工程任务上仍然是一个必须认真对待的对手。
Google 也会难受,因为 Gemini 体系虽然平台化能力强,Gemma、NotebookLM、Gemini Live 都在努力变强,但在这张 Anthropic 官方跑分图里,Gemini 3.1 Pro 在多项测试里输了。Google 的优势在生态和分发,Anthropic 的优势在最强模型的尖刀能力。
国产模型也会被迫重新回答一个问题,便宜之外,还能不能让用户把最难的任务交给它。DeepSeek V4 的 1M 上下文、开源权重和极低价格很有杀伤力,小米 MiMo 的降价也会继续推动 API 市场往下卷,但 Fable 5 这种模型的存在,会一直提醒市场,便宜模型能覆盖大量任务,可最难的 5% 或 10%,仍然可能被最贵的模型拿走。

(图源:Anthropic )
Fable 5 的真正市场意义就是,它不会让所有企业马上换模型,便宜模型的价值也不会消失,但它把大模型竞争推向了一个另一场竞争,未来市场会同时需要两类模型,一类是便宜、稳定、可大规模调用的工作牛马;另一类是昂贵、强悍、带着护栏、专门处理高价值任务的顶级工具。
Anthropic 有点像在用 Fable 5 告诉整个行业,我们不参与每一场价格战,但我们卖的就是最有价值的部分,你不得不在采购时把我列入考虑范围内。
说白了,模型越强,问题越现实,它到底卖给谁,卖多贵,出了事谁负责,这些过去看起来很遥远的问题,现在已经被Claude Fable 5 摆到了桌面上。





