



























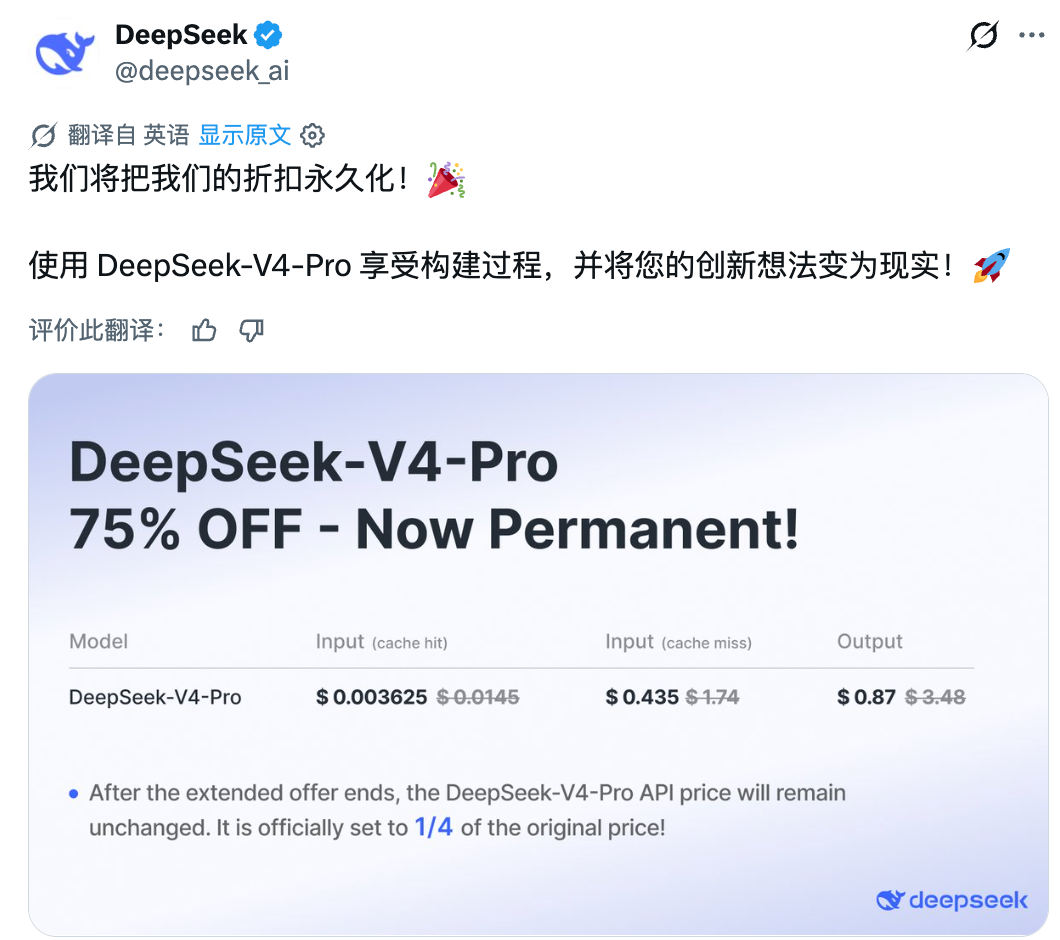
DeepSeek宣布将V4-Pro API 75%的折扣「永久化」,全球同步生效。
最终的价格体系:基础输入价格由 1.74 美元 / 百万Token降至 0.435 美元 / 百万Token,输出价格由 3.48 美元 / 百万Token降至 0.87 美元 / 百万Token。针对全 API 产品线的输入缓存命中,DeepSeek 实施了更大幅度的让利:0.003625 美元 / 百万Token,全是拼多多式的地板定价模式。
包括X在内的社交媒体随即出现了一波呼声:梁文锋就是AI圈的赛博菩萨、锋神、梁圣。情绪并不来自于便宜本身——DeepSeek一直被称为AI拼多多,C端免费,B端廉价,全世界都习惯了它的便宜,但这一波降价难的地方在于:全世界AI都在涨价。
有报道称,梁文锋在DeepSeek正在推进的创纪录的A轮融资中,个人将出资最高200亿元人民币,占融资总额的40%。绝大部分公司融资时第一件事是强化现金流,让业绩更好看,但梁文锋并不打算用商业化的饼去吸引投资人,而是坚持开源、追求AGI,这波降价还真是说到做到。上一次这么勇敢地表示不想赚钱的是拼多多,24年它的联创在电话会对投资者们明确表示:“从 Q3 开始我们的利润将逐渐下降,短期内不会反弹。从长远来看,盈利能力的下降是不可避免的。”股价暴跌。
Sam Altman口口声声说AI民主化,但OpenAI这家公司正在飞速走向它名字的反面:CloseAI。梁文锋却在身体力行地让每个人、每个企业都尽可能普惠地使用AI。但梁文锋真的是活菩萨吗?并不是。他是企业家,开源普惠只是商业模式的选择,这在当下难能可贵,在未来将愈发稀缺。
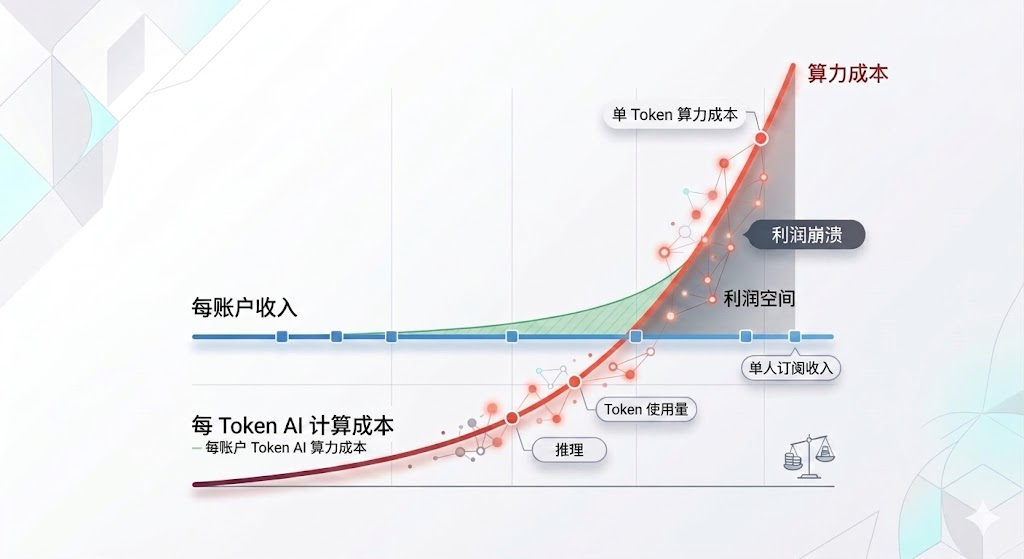
因为:AI正在变得越来越贵。
本周,微软取消了内部的Claude Code许可证,因为基于token的计费方式高得让其招架不住。微软曾重金扶持OpenAI,还为A社提供Azure云服务,拥有所有企业艳羡的云计算资源,但Token成本依然让其肉疼。无独有偶,Uber的CTO在今年4月向管理层汇报了一个令人尴尬的情况:公司为2026年全年准备的AI预算,在四个月内被花完了,其中95%的工程师每月都在用AI编程工具,70%的提交代码由AI生成,原话是:“I’m back to the drawing board because the budget I thought I would need is blown away already.”。
大厂Token预算烧得比预期的快很多,固然有公司员工“拿豆包不当干粮”可劲烧Token的原因,但AI正在变贵才是Token预算紧张的根源。美国AI软件价格在过去一年上涨了20%至37%。Anthropic、OpenAI和Google御三家在过去六个月内都悄悄提高同样AI输出的实际价格。
(图源:X)
原来流行的声音是“AI越大规模应用,工业化程度越高,成本越低,企业越爽”,结果天真了。
而且这个趋势不会逆转。价格由供需而非成本决定,但AI的供需关系在26年已经彻底反转了。以前大厂求着大家用AI,要教育市场、推广技术,AI一直是有补贴的,你喝过多少杯千问的奶茶了?现在呢?大家越来越主动用,“吸了第一口就离不开”,AI编程,AI文档,AIGC甚至AI搜索,都越来越普及,AI补贴时代彻底结束了。
用的人越多,需求量越大,token资源越紧张,所以算力短缺从GPU外溢到CPU、存储甚至带宽,Intel、美光、SK海力士、三星电子、闪迪以及国内的江波龙、两长们跟着英伟达一起吃肉。半导体巨头们26年成倍增长的营收来自哪里?根本从来就不是OpenAI-甲骨文-微软的三角闭环投资好吧?企业们的肉疼这才哪跟哪?而ChatGPT、Claude、Gemini、豆包等AI产品强调免费与付费的“等级森严”,也会让个人用户越来越纠结。
这就像网约车:疯狂的时候你可以免费坐专车上下班,资本替你买单。用户习惯建立后,补贴结束,价格回归到正常水平,该坐地铁的还得坐地铁。AI也一样。所以在大行业Token都上涨的大背景下,DeepSeek坚持把价格往下砍,这个动作就不再只是“赛博菩萨”的个人魄力,而是展现出一种反向定价权:我能如此廉价,还能正常运转,质量还不掉线。
只要梁文锋愿意,DeepSeek完全不用廉价至此。于是大家开始担心:DeepSeek会成为AI时代的Linux吗?影响力巨大,但赚不到大钱。Linux对IT产业的贡献比Windows、比安卓都要大得多(安卓本身基于Linux内核),但它是开源的,商业上没有催生出微软、Google这样的巨头。DeepSeek当下影响力巨大,商业能力远不如硅谷御三家,甚至无法与国内的Kimi、MiniMax、智谱三家抗衡。25年四小龙营收排序:智谱(2025年收入7.24亿元)> MiniMax(2025年收入约5.6亿元)>月之暗面(约2亿元)> DeepSeek(未知但更低)。
梁文锋做AI量化来钱,个人能拿出200亿投资DeepSeek,但“用爱发电”的故事无法长久。
还有开源模式下,别人也能蒸馏、部署、二次训练,DeepSeek的技术护城河会越变越薄。所以你总能看到这样的「刷榜」新闻:智谱GLM-5.1开源后在SWE-bench Pro基准测试中刷新了全球成绩,小米MiMo-V2.5-Pro登顶全球开源大模型榜首……麻省理工学院与Hugging Face的联合报告显示,过去一年中国研发的开源模型全球下载量占比达17.1%,反超美国的15.8%,全球第一。
难怪硅谷越来越多的声音在说:一定要有美国版的DeepSeek,不能眼睁睁看着AI产业再上演Shein、Temu或者TikTok的故事。“如果美国没有一个开源冠军崛起,世界将运行在任何一个能产出最强、最稳定、最便宜、可定制、可扩展、适配个人与商业需求的开源模型与开源软件的国家手中。”涉及到大国竞争的话题往往有些宏大, 但背后的竞争却是实打实的。
DeepSeek崛起背后,本就有自主替代的叙事。V4支持昇腾让人欢欣鼓舞,国产算力驱动下,DeepSeek当前展现的价格竞争力还只是前菜。在技术报告中,DeepSeek表示下半年昇腾950超节点批量上市后,V4-Pro的价格还会大幅下调,好日子还在后头呢。
还有高级AI人才优势,AI人才都贵到“奢侈级”水平,但中国的相对便宜,雷军千万年薪从DeepSeek挖走罗福莉成了新闻,同期扎克伯格却要拿10亿美元挖人,包括Acqui-hire。但10亿美元的人和千万年薪的人做出来的东西差距显然没有700倍这么大,AI人才的价差其实会转化成Token生产体系的系统性的价差。
更大的竞争力还有能源体系,这是黄仁勋AI五层蛋糕的第一层。
AI的尽头是算力,算力的尽头是电力。2026年4月,DeepSeek招聘放在内蒙古乌兰察布的数据中心高级运维工程师和高级交付经理,这说明它要去西部建Token工厂,将成本优势从软件层压到物理层。上一次我在文章中写到乌兰察布是当快手在这里建设数据中心时:距离电厂近,气候适宜好散热。而且中国西部绿电价格约0.2-0.3元/度,仅为欧美的1/5到1/4。
不只是西部绿电有竞争力。国际能源署2025年数据显示,中国发电总装机容量已经超过2300GW,占全球约22%,全球第一;美国约1300GW。更关键的是,中国拥有全球最完整的电力结构:火电、水电、风电、核电、光伏全部齐全。数据显示,中国工业电价长期维持在0.06到0.08美元/kWh,美国加州工业电价已经接近0.18美元/kWh,德国部分地区甚至超过0.25美元/kWh,这意味着同样训练一个万卡集群,中国天然比欧美便宜几十个百分点。
AI大模型的运营成本中,电力成本占运营总成本的比例高达60%-70%,不只是模型跑要用电,还有散热这个大头,基建狂魔都将数据中心直接给建到海底了,一边海上风电就近输入,一边海水循环免费散热。还有“西电东送”、“东数西算”这些大手笔,电力与算力区域调度能力都极强,贵州、内蒙古、宁夏这些地方本来就是“东数西算”的核心节点,AI算力中心往西部搬的通路早就备好了。
用中国的AI,本质就是用更有竞争力的能源体系训练出来的AI——更经济、更普惠的AI。这是为什么春节后kimi、minimax们的海外营收会暴涨的原因之一,不只是算法更强,而是开了电价外挂。
英伟达能够定义高端算力的价格,但DeepSeek们却在掌握Token的定价权。你可能会说,AI便宜无好货。AI确实是一分钱一分货,DeepSeek V4也只是将开源与闭源的差距缩小至历史最小水平,官方坦言与GPT等顶尖模型的客观差距,而且还不是多模态的,能识别图片,但不能生成。
但这并没有阻止社区涌向DeepSeek。原因是:大部分真实商业场景并不需要每次都调用世界最强模型。咨询、客服、摘要、翻译、代码补全、企业知识库、自动化流程,这些东西要的不是最高智力,而是“勉强能用+足够便宜+足够稳定”。当DeepSeek V4的推理成本只有GPT-5.5的约1%(Flash)到11%(Pro)时,一个企业用同样的预算可多调用数十倍token,尝试更多prompt链条,迭代更多的agent工作流,最终出的活儿反而有机会更好,毕竟AI本身就是一个“概率”游戏,只要足够便宜,凑合着用能拿到结果有什么不可以?

所以,AI越贵,DeepSeek的便宜就越有价值,DeepSeek这家公司就会越有价值,梁文锋和他的投资人想得比谁都清楚。





