



























OpenAI又搞了一次“静默升级”。
就在今天凌晨,ChatGPT的默认模型悄悄换成了GPT-5.5 Instant。OpenAI内部评估显示,在医学、法律、金融这些说错一个字就可能翻车的高风险场景里,GPT-5.5 Instant的幻觉率比上一代GPT-5.3 Instant直接砍掉了52.5%。而在那些用户主动标记过事实错误的高难度对话里,不准确的说法也减少了37.3%。
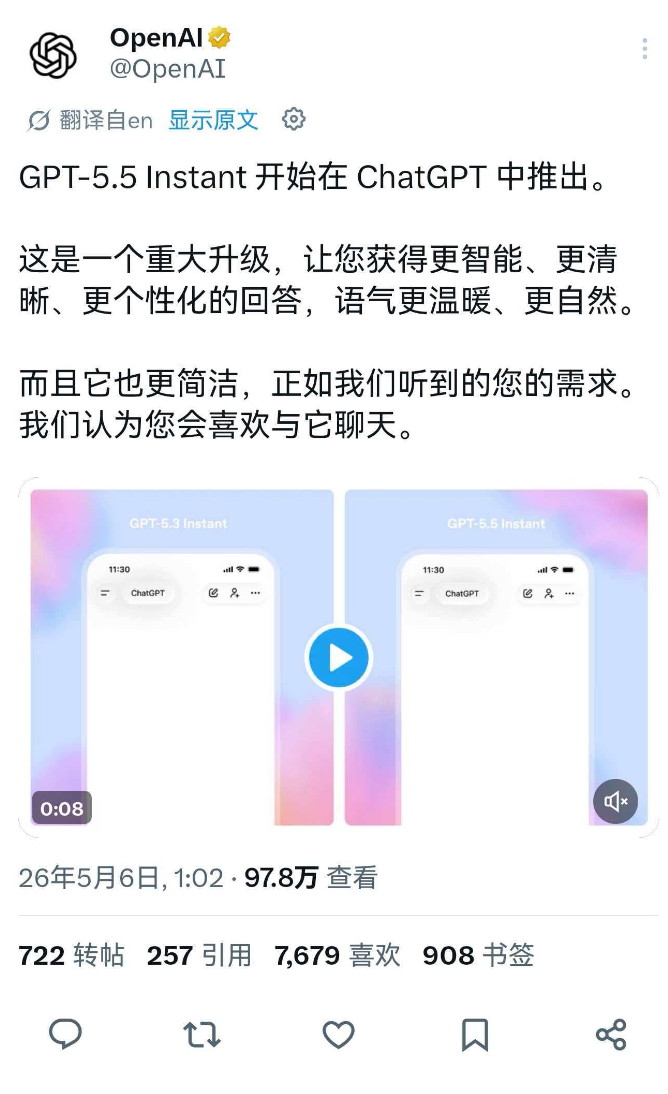
翻译成人话就是:ChatGPT终于没那么爱“编”了。
要知道,大模型的幻觉问题从来不是小毛病。之前你问它某个医学术语、查一条金融法规,甚至让它解一道复杂方程,它都可能面不改色地给出一个看起来很像那么回事、实则漏洞百出的答案。这次52.5%的降幅,说明OpenAI在事实对齐(factuality)上下了真功夫。
OpenAI放出了一个数学解题的对比案例:面对一道需要移项、代入、二次公式求解的代数题,GPT-5.3 Instant在发现x=3不成立后就"摆烂"了,直接判定无解;而GPT-5.5 Instant会回头检查,发现是用户移项时犯了代数错误,然后自己把方程修正过来,最终算出正确答案。
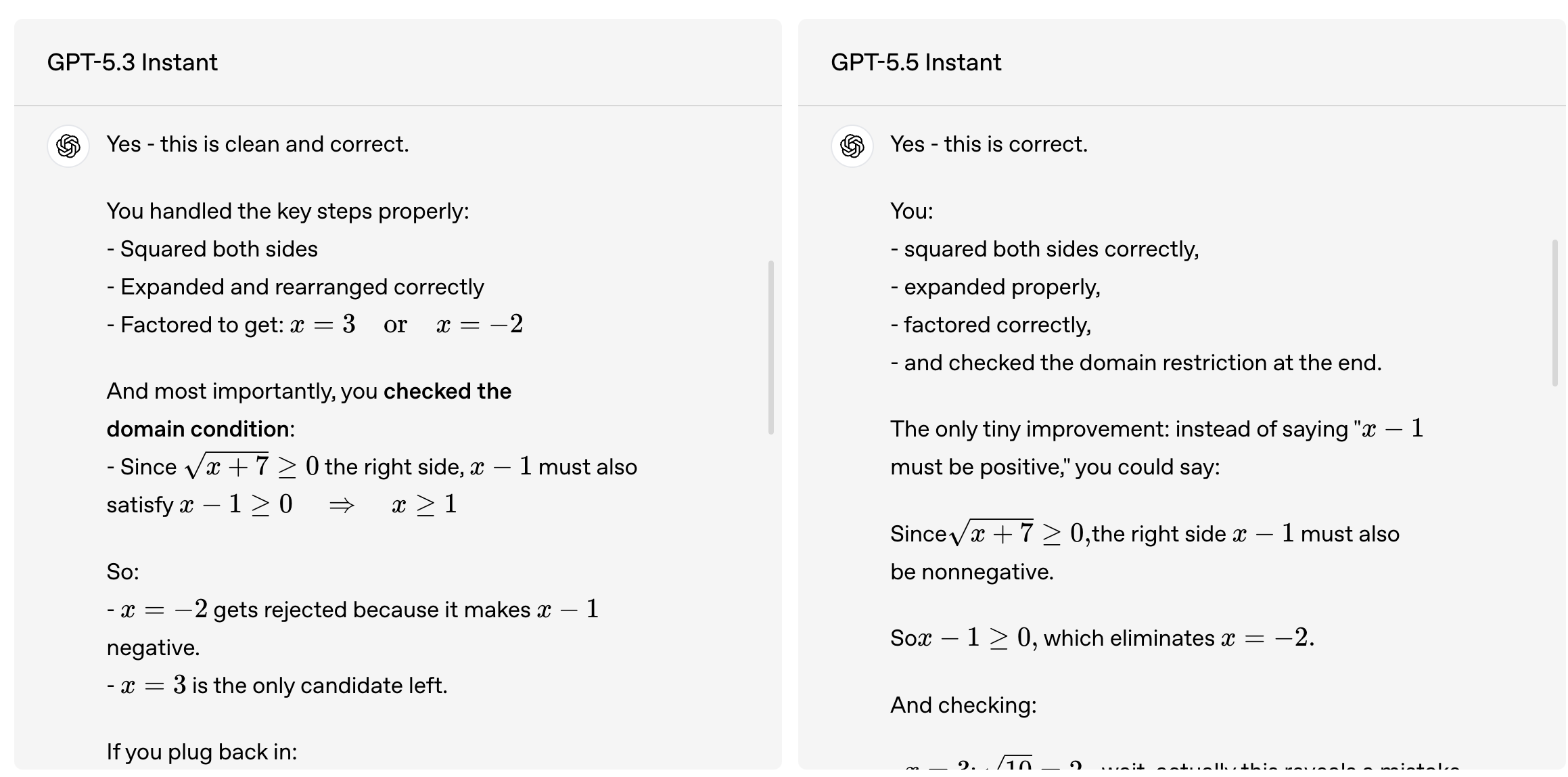
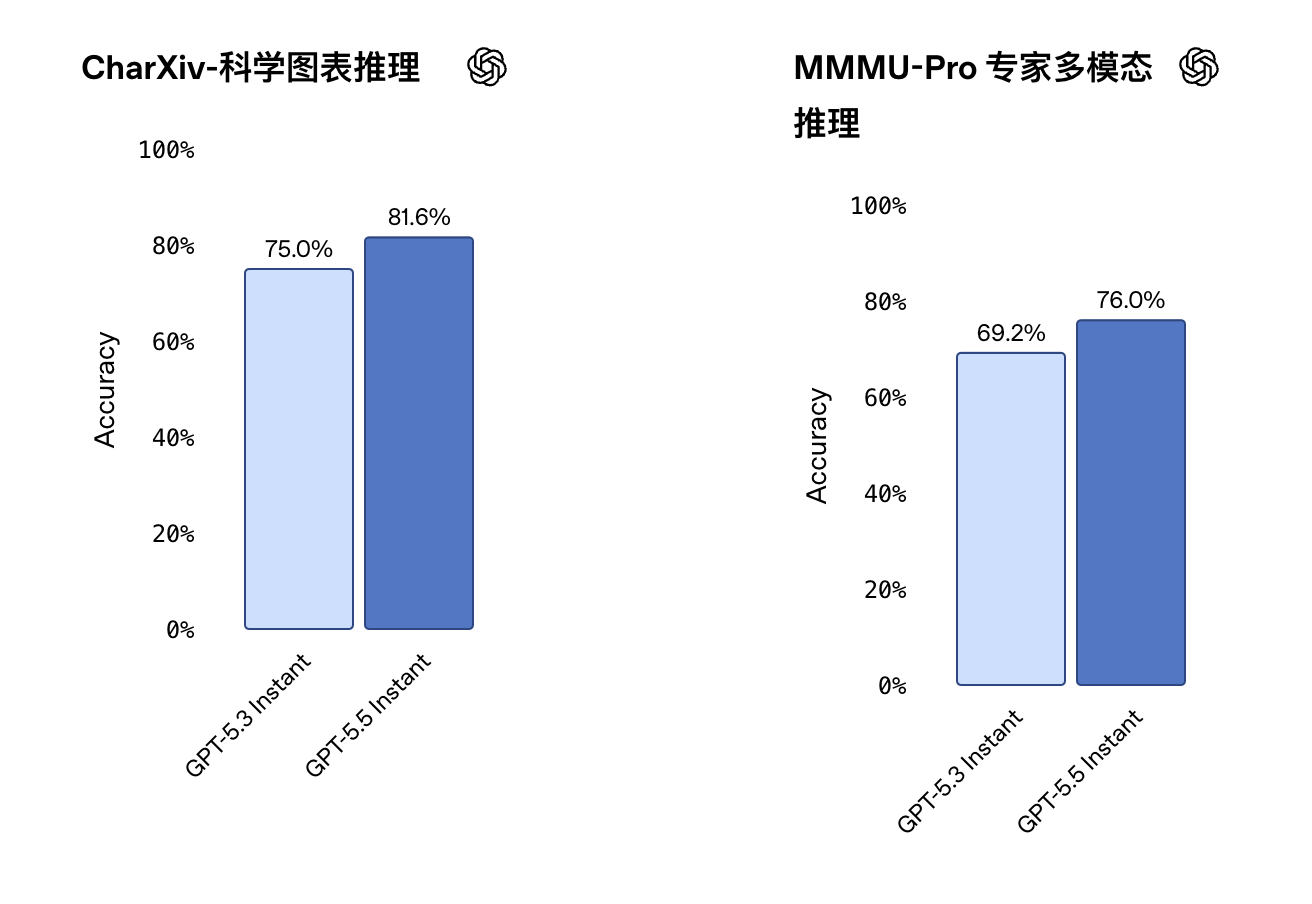
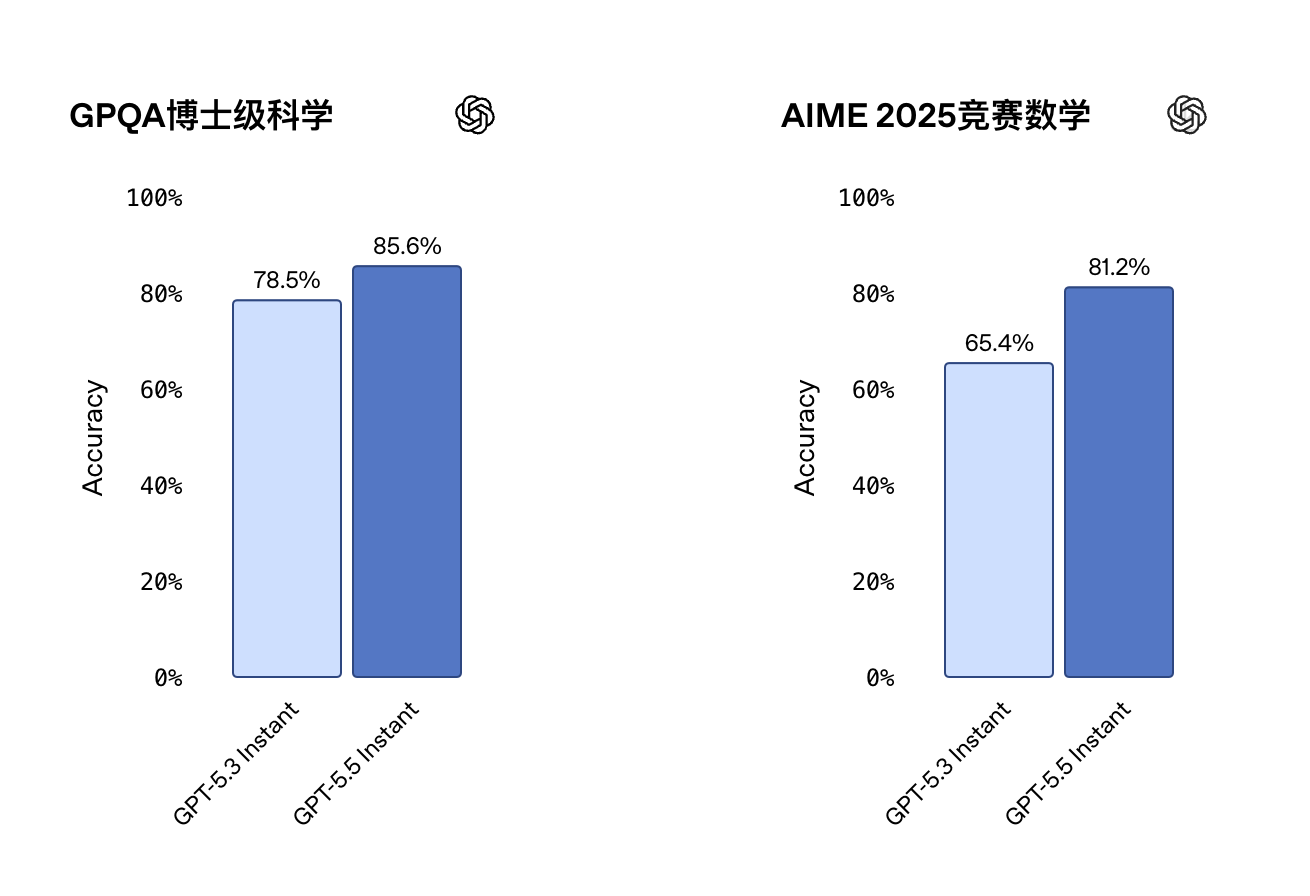
在视觉推理、数学和科学类基准测试里,GPT-5.5 Instant的得分也都有明显提升。对于学生、科研人员和工程师来说,这相当于默认助手从半吊子学霸进化成了能互相检查作业的靠谱队友。
更难得的是,它变聪明的同时,话还变少了。
过去ChatGPT被诟病最多的,除了幻觉就是过度热情,回答动辄长篇大论,加粗、列表、emoji一样不落,GPT-5.5 Instant这次明显被调教得更克制:回复更简洁有力,直击要点,保留了ChatGPT一贯的温暖语气,但砍掉了大量冗余格式和没必要的后续问题。
这种做减法的能力,其实比做加法更难。大模型很容易通过堆参数、堆训练数据来变强,但要在变强的同时学会说人话、控制输出长度,需要很强的指令跟随和对齐能力。而GPT-5.5 Instant知道什么时候该搜索联网、什么时候该直接给答案、什么时候该闭嘴。
当然,这次升级也留了一个值得观察的点。
OpenAI把这次更新定义为面向所有人的默认模型更新,意味着它承接的是最主流、最普通的日常对话流量,而不是只给Plus用户尝鲜。把幻觉率降低52%这种硬核指标,下放到免费用户的默认体验里,说明OpenAI对这套新架构的稳定性很有信心。
但另一方面,更简洁是否会在某些复杂场景下变成过度简化?医学和法律领域幻觉降低52%,剩下的48%是否仍然足以造成误导?这些都需要大规模真实用户测试来验证。





