



























开年这三个月,OpenClaw真是火得一塌糊涂。
我身边不管是懂科技的,还是不懂科技的,大家都在幻想只要装上这玩意,它就能帮你自动点鼠标、回邮件、整理本地文件夹,甚至连写代码、做课件、炒股票这种掉头发的活儿都包圆了。

(图源:雷科技)
当然了,他们也是想借着这股东风,顺便卖卖自家的新一代酷睿Ultra 300处理器。
雷科技今天受邀来到现场,趁机帮大伙好好扒一扒,这套方案到底是真的能普惠大众,还是又一套吸引你更新换代的话术呢?
“智能体PC”:集成AI智能体的个人电脑
这一开始呢,英特尔主讲人就给咱们讲产品定义了。


理论上,
哪怕是入门级的Ultra 325,也能在一定程度上运行更小体量的本地大模型来辅助。

本地部署不用愁,表现比预期要好
先说部署,之前咱们雷科技折腾OpenClaw的时候,整个公司就没几个人能弄明白这玩意究竟咋整,就连开始部署前的准备都要小半天。
当时某位同事不幸被抽到去这个项目,然后他为了在一台Mac Mini上跑通这个开源项目,居然折腾了整整一天半,各种配环境、搞接口,稍微错一行代码整个系统就直接罢工。
到了英特尔这里,本地部署肯定是不用愁了,他们的合作伙伴基本上都有一套图形化、一键式的OpenClaw部署应用,哪怕是傻瓜也能按步骤给自己的电脑整上龙虾。
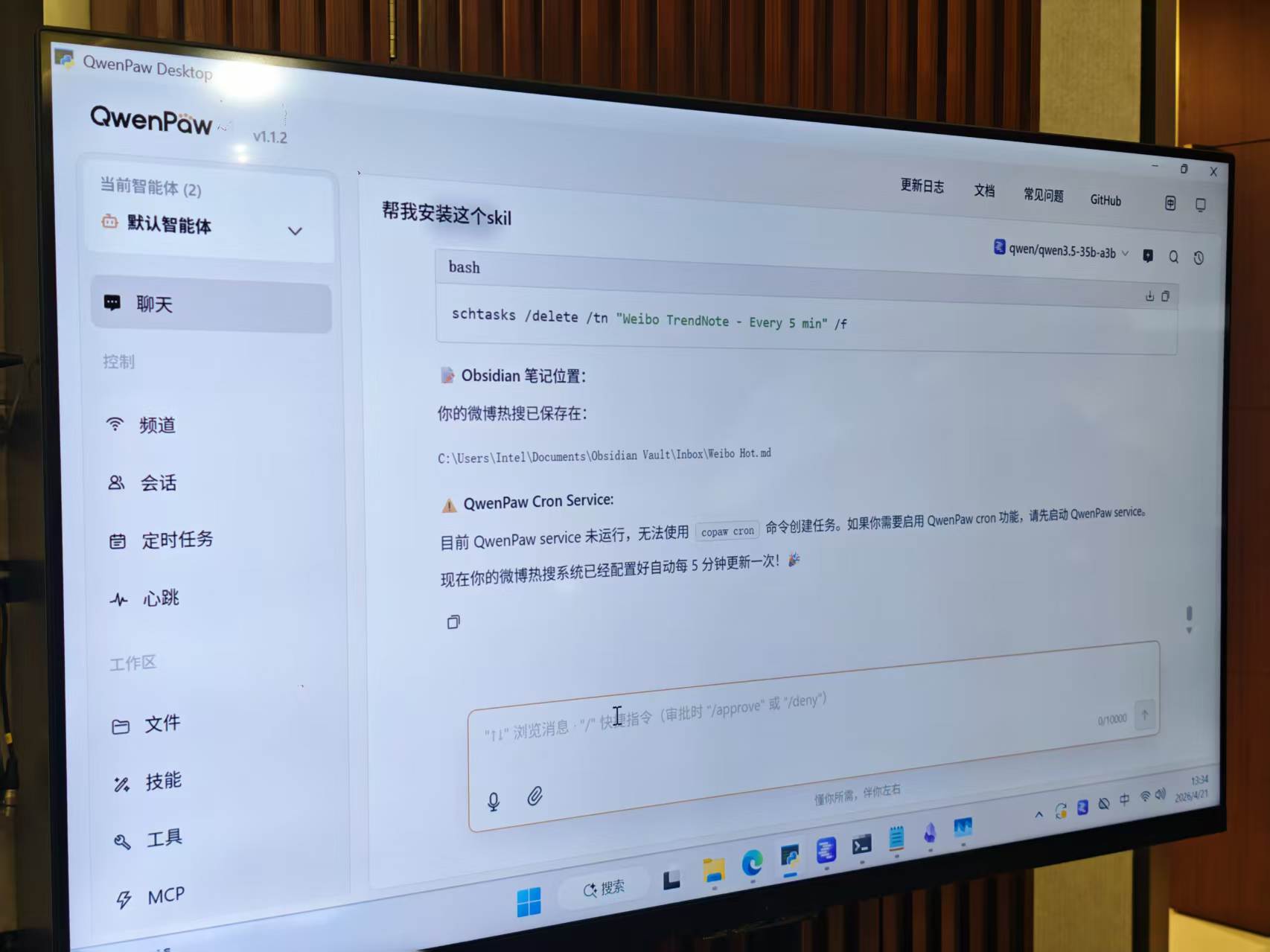
(图源:雷科技)
部署完成后,自然就来到了体验环节。
从现场运行的Demo来看,英特尔在本地部署的是Qwen3.6-35B模型,这个参数量自然是经过控制的,但也恰好符合现场布置的这些电脑的硬件需求,用Arc B390核显搭配上32GB显存,刚好能达到60tokens/s的生成速度。

(图源:雷科技)
要知道核显毕竟是核显,遇上更高参数的本地大模型,这套配置的生成速度必然会显著下降。
现在的话,生成速度应该是刚刚好,60tokens/s属于感受不到明显延迟的水平。
至于本地模型的智商,那肯定是比不上完整的在线大模型,但是处理一下基础的智能体任务倒是问题不大,什么资料检索、文件搜集、定时推送,甚至针对特定文档的结构分析都能完成。
我甚至用Z-image生成了几张图,用时都控制在1分钟以内。
(图源:雷科技)
你还别说,这个做法确实安全不少,毕竟谁也不想让自己电脑里的学习资料或者公司机密全盘暴露在云端服务器上吧。
不过本地大模型,始终参数不够到位,如果只用这玩意,任务稍微复杂一点就会开始胡言乱语,甚至执行到一半突然卡死。
现场给发票进行OCR的Demo演示,就很不巧地卡住了。
至于端云协同的部分,按理来说,在这个Demo里,本地大模型会把复杂的推理任务进行解构,只把最关键的搜索指令和逻辑框架打包发给云端的超级大模型。
等云端算完把结果传回来,本地的模型再接着接手,默默帮你排版出图。
(图源:雷科技)
但是实际上现场大部分任务都会自动走云端,或者推荐用户走云端,要调用本地应用反而需要特定的指令。
好消息是,这一套组合拳打下来,后台Token消耗应该能降低不少,至少不会像我们以前测试同类产品时动不动就烧掉几十块钱调用费了。
不过话说回来,这套混合体验离完美还差得远。
首先,这些应用加载的本地大模型间彼此是独立运行的,32GB运存显然不足以运行所有本地大模型,只能在需要调用时开启对应的大模型进行操作,现场也只有一款设备是在同时运行多个本地大模型的。

(图源:雷科技)
其次,有时候本地和云端交接棒的时候还是会卡壳,甚至偶尔还会出现本地模型理解错意思,导致鼠标在屏幕上原地转圈圈的尴尬场面。
考虑到这些只是拿来分享的Demo,出现意外状况也算是在情理中了。
与其指望云端算力降价,不如部署到终端设备
骂的就是你,那个叫Claude的不人不鬼的玩意嗷。

2026第十九届北京国际汽车展览会将于4月24日至5月3日在北京中国国际展览中心(顺义馆)和首都国际会展中心(新国展二期)举行,本届车展以“领时代·智未来”为主题,集中展现汽车工业的更多黑科技。
比亚迪、小米、鸿蒙智行(问界等)、小鹏、蔚来、岚图等头部品牌集结,多款重磅新车首秀;地平线、Momenta、卓驭等供应商集体秀肌肉,AI大模型深度赋能,高阶智驾、动力电池、超快充技术等前沿科技集中亮相,看点拉满!
雷科技旗下「电车通」将派出报道团直击现场,以“关注电动车,更懂智能化”的专业视角,带来一线独家报道,敬请关注!






