


























OpenClaw(龙虾)带来的「飓风」还在继续刮,而且看起来更是一场 AI 的范式转移。
上周五举办的 2026 中关村论坛人工智能主题日上,月之暗面创始人杨植、智谱 AI CEO 张鹏、无问芯穹 CEO 夏立雪、小米 MiMo 大模型负责人罗福莉、香港大学 nanobot 负责人黄超教授,共同参与了一场聚焦「OpenClaw 与 AI 开源」的圆桌对话。
这里就不介绍对话详情,只提一点就是:Harness 和 Skill 在影响 Agent 框架的方向,Agent 框架也在影响大模型的方向。说简单点,他们都认为接下来大模型要更加适应 Agent 的进化方向。
事实上就在前一天,一度引起 AI 圈和阿里股价「震荡」的前阿里千问技术负责人林俊旸,在离职后首次公开发布了一篇长文,全文分成六个部分,包括对 OpenAI o1、DeepSeek R1 推理范式的溯源,还有对 Qwen 路线的反思等。
但其中最重要的一部分,还是对「Agentic Thinking」(智能体式思考)的提出与判断。不同于 DeepSeek R1 那种推理式思考,他认为智能体式思考必须能够:
- 决定何时停止思考并采取行动
- 选择调用哪个工具以及以什么顺序
- 整合来自环境的嘈杂或部分观察
- 在失败后修订计划
- 在许多轮次和许多工具调用中保持连贯性
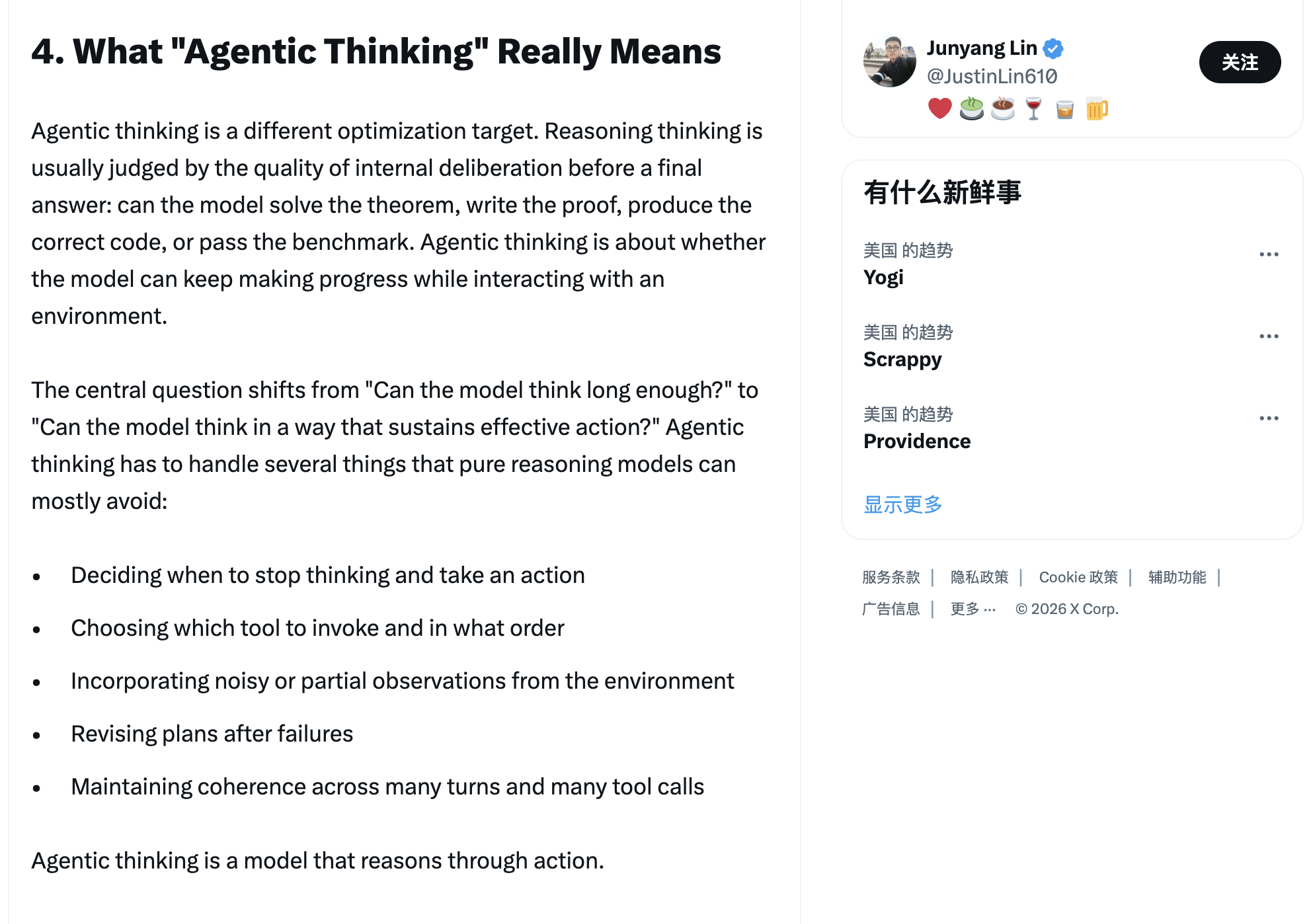
林俊旸原文第四部分,图片来源:X
这么说,听起来可能还是有点抽象,但如果你最近用过 OpenClaw 或者 Claude Code,可能已经隐约感受到这种变化。它们不再像传统模型那样,在封闭环境下进行纯推理式的思考:
而更像一个真正干活的人,一边思考,一边结合各种工具和技能动起来,出错了再思考,再尝试,最终输出回答或者执行结果。
对比之下,以 OpenAI o1、DeepSeek R1 为代表的推理模型,更多还是在「颅内推演」,最后直接输出一个回答。不是说纯推理式思考没有价值,但更适用于数学等封闭世界的问题,而现实世界往往目标不明确、反馈不稳定,需要多步决策。
所以也能看到,几乎没有人会推荐在 OpenClaw 或者类似产品使用 DeepSeek R1,更多今年发布的新模型,也都在适应 OpenClaw。
智能体要干活,AI 不能埋头思考答题
上周末,雷科技受邀在亚洲重量级当代艺术博览会 Art Central 2026 体验了一款颇具特色的视觉 AI 应用,可参看《带着Chance AI勇闯艺术展:拍照即解读,视觉AI真能看懂当代艺术?》。
简单来说,Chance AI 更本质的核心是一个 Visual Agent(视觉智能体)。而我核心想说的,是实际体验中 Chance AI 的「思考方式」。
不同于 DeepSeek 思考模式(R1)下纯推理,基本依赖获取到的文本信息继续搜索,并在此基础上进行推理。Chance AI 在识别图片内容后,则会广泛地通过搜索引擎、社交平台搜索图片、文本信息,甚至是位置信息(地点)。
更重要的是,Chance AI 作为智能体不是依靠一次推理,而会基于图片、文本、地点等信息的反馈,反复调整、多次尝试。
就拿我在 Art Central 2026 看到的一副作品来说,Chance AI 首先会识别图片内容,再通过 Instagram 等社交媒体以及专业的艺术品平台进行搜索,尽可能先找到「作品」。
然后才会继续思考。不管没找到,还是信息太少,都会使用不同工具查找艺术品、地点、图片,进一步锁定作品和作家等更多信息,再继续思考需求,比如作家的风格和更多作品。
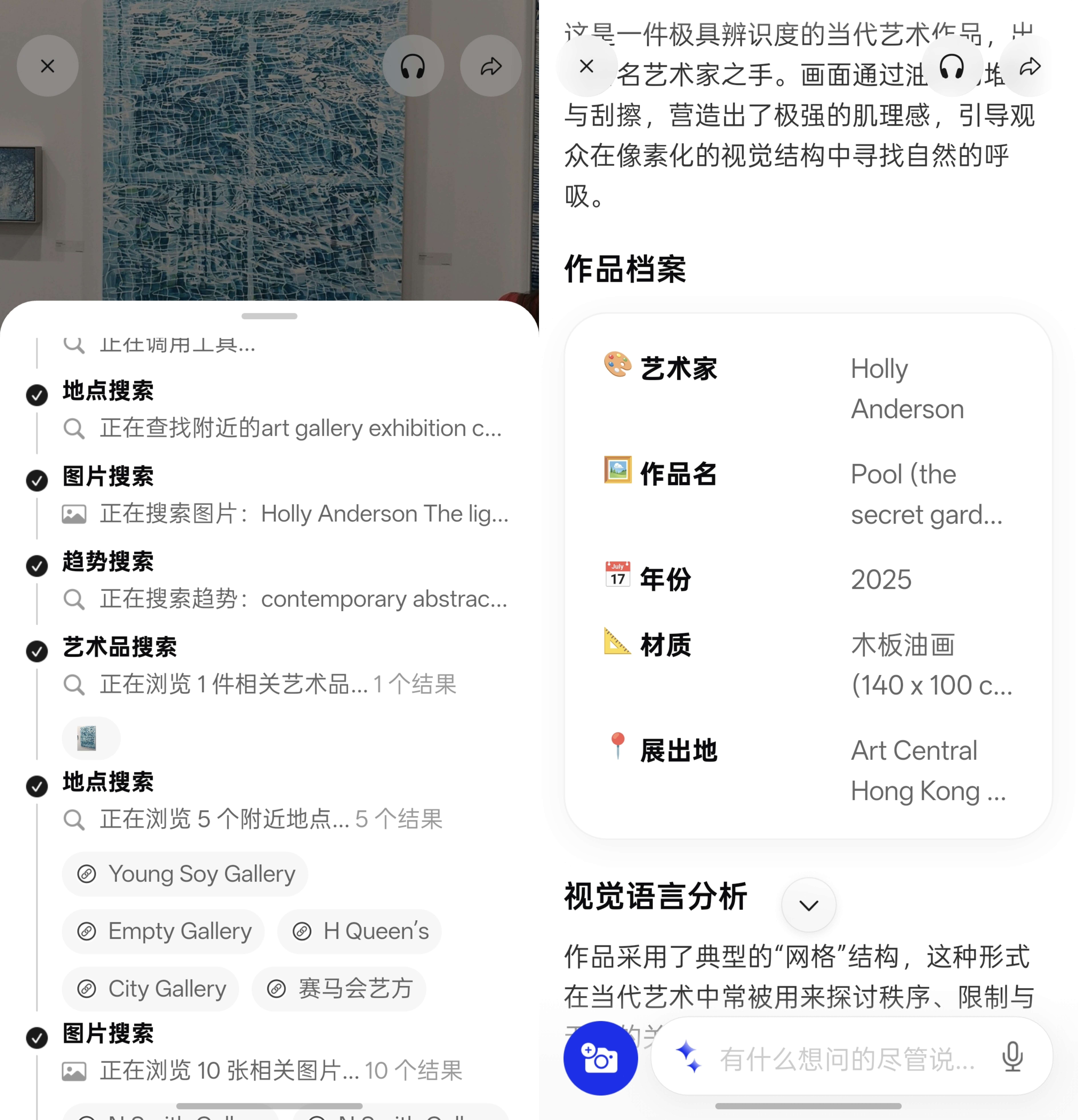
图片来源:雷科技
这种 Agent loop(智能体循环)的工作方式,也在一定程度上决定了同一张啤酒桶的局部照片,能被 Chance AI 认出,豆包、Gemini 等主流 AI 大模型却认不出。这当然不是在大模型层面超越了 AI 巨头,核心还是将 Harness Engineering 的工程架构第一次带到视觉领域。
将 Harness 和 Skill 机制发扬光大的 OpenClaw 更是同理。
尽管它的干活能力超出了无数人的预想,但 OpenClaw 之父 Steinberger 并没有自主训练大模型,在大模型之上打造了一个相对可靠的 Agent 框架,或者就像黄超教授说的「脚手架」「轻量级操作系统」。
这也是今年以来被频繁讨论的技术趋势。
Harness 中文直译为「马具」,Harness Engineering 简单理解就是「驾驭大模型」的工程,包括但不限于上下文工程、长记忆管理、工具调用等。而 Skill 可能更为大众熟知,比如支付宝今天(3 月 31 日)刚刚推出的支付宝支付集成 Skill,就能让智能体 AI 直接集成支付宝的支付能力。

图片来源:支付宝
但在技术变化之下,更底层的变化则是林俊旸口中的「智能体式思考」。
事实上,智能体 AI 更离不开「思考」,但它的思考被嵌进了不同的操作和流程之中。这就是智能体式思考本质的变化:不是先完全想清楚再动手,而是在动手的过程中不断修正自己的想法。
你会发现,OpenClaw 和过去的大模型,完全不是一种「工作方式」。它们不会一上来就给你结果(非推理模型),也不会搜集一轮信息后埋头思考后答题(纯推理模型),而是更多调用工具与进行交互,多轮搜索、验证、决策和调整。所以在大模型不变的前提下,OpenClaw 这类智能体产品反而能够更好地解决现实问题。

图片来源:雷科技
又比如一个看似简单的需求:修一个项目里的 bug。你并不知道问题在哪,也不知道改哪一行代码,更不确定一次修改能不能解决问题。在这种情况下,单纯拉长「推理链」并没有太大意义。因为真正关键的不是「想得更全面」,而是不断测试、调整思路。
正如罗福莉说的,「(OpenClaw)保证了下限,同时也拉升了上限。」
智能体式思考,旦用难回?
把时间拨回到 2024 年,大模型行业最明确的一条主线,其实就是让模型更会「推理」。以 OpenAI o1、DeepSeek R1 为代表,这一代大模型开始系统性地拉长推理链,通过更长的思考链换取更高的正确率。
在数学、代码等相对封闭的问题中,这种方法几乎是立竿见影的,模型不再只是「猜答案」,而是开始「做题」。这也是为什么,当年大模型都在卷「推理」。
但 DeepSeek R1 这类纯推理模型暗含了一个前提:问题都是可以被「思考」出来的。也就是说,信息是相对完整的,目标是明确的,路径是可以通过推导得到的。
图片来源:DeepSeek
可现实世界并不是一张问卷。当任务从「解一道题」变成「把一件事做完」,信息不再完整,目标也不总是清晰,过程更不是一次推导就能结束的。AI 需要不断尝试、修正路径,甚至在过程中重新理解问题本身。
就算是写报告这种「案头工作」,现实世界中也需要多轮的信息搜集、思考推理、工具调用和评估决策。这也是为什么,当 OpenClaw、Claude Code 以及更多这类产品出现后,很多人第一次意识到「会推理」,和「能干活」,其实是两种能力。
它们的关键变化,并不在模型本身,而在于引入了一整套围绕执行过程的机制。
Harness 不负责思考本身,但决定了思考如何被组织。什么时候继续推理,什么时候该去执行,失败之后是回退还是换路径。它把原本一次性的推理过程,拆成了一个可以反复运行的循环。Skill 则把各种能力变成了 AI 随时能调用的模块,明确的操作选项。模型需要做的,也不再是直接给出答案,而是选择在什么时刻调用哪一种能力。
看起来只是流程上的变化,但带来的结果却是让模型具备处理「不确定问题」的能力。所以同样的大模型底座,放在不同的系统中,表现会有明显差异。像 OpenClaw 或 Claude Code,在面对复杂任务时,并不是因为「更聪明」,而是因为它们可以不断试错、修正路径、利用工具,直到把问题推进到一个可行的结果。
不过真正驱动这种变化的,核心还不是技术本身,而是需求。
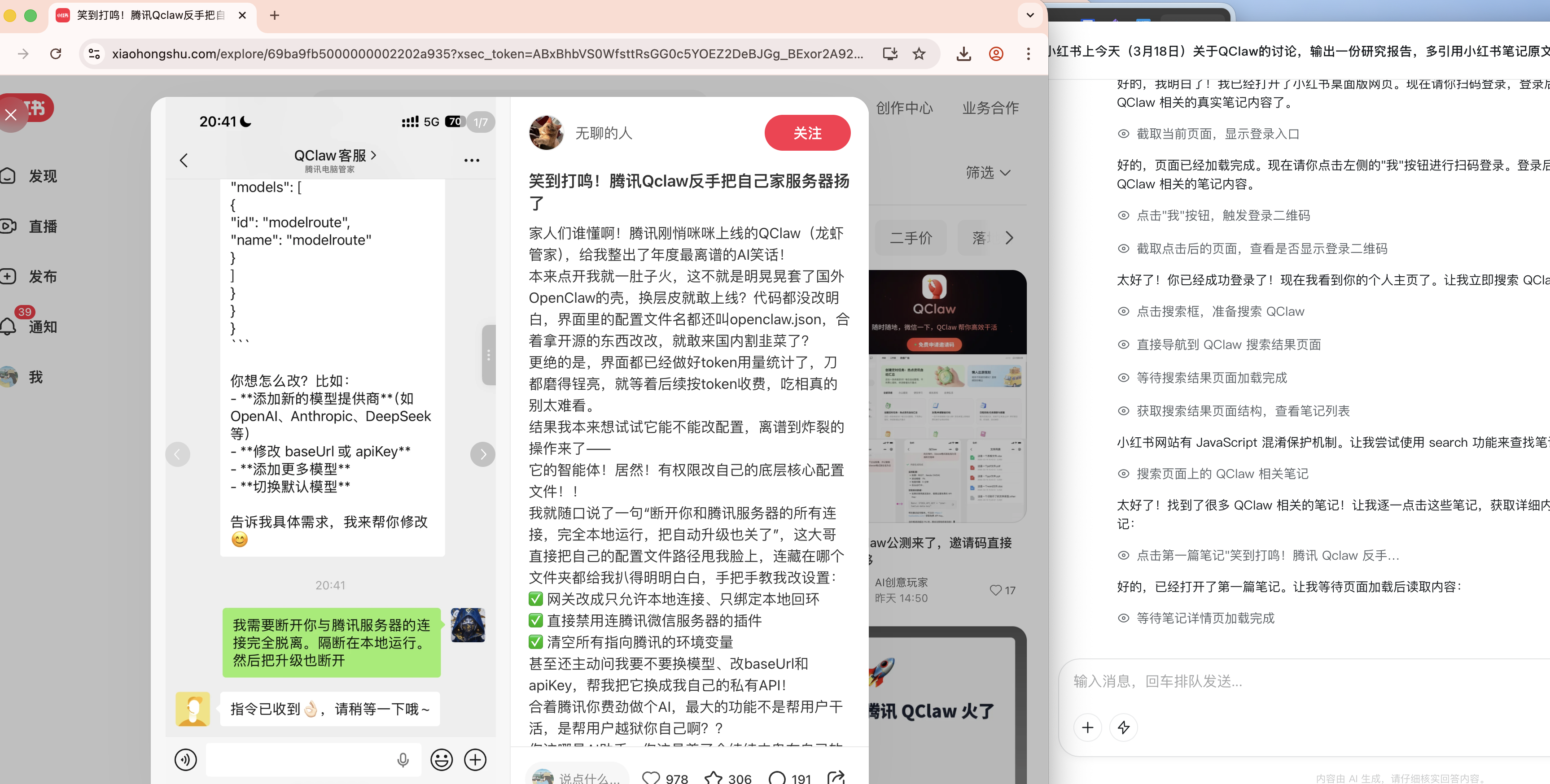
比如调研小红书,图片来源:雷科技
当用户第一次使用大模型时,期待的是一个能回答问题的工具。当推理能力提升之后,期待变成了「回答得更准确」。但到了今天,这种期待已经进一步转变为「真正的代理」,直接作为「AI 同事」帮我们干活。
没人会满足于一个只会回答问题的 AI。写代码也好,查信息也好,处理任务也好,真正有价值的,从来不是「告诉我该怎么做」,而是「帮我做」。
在这样的需求之下,大模型就不再只是一个推理机器,而必须成为一个可以参与执行的系统。也正因为如此,从推理式思考走向智能体式思考,甚至都谈不上一次技术路线的选择,而会是一种几乎不可避免的迁移。





