



























当外界还在讨论谁才是机器人领域的当红炸子鸡时,一家名为无界动力的初创公司正以极其凶猛的姿态杀入大众视野。
6月29日,这家成立于2025年的年轻企业,正式发布了全球首个“长时序双向物理因果链”隐空间世界模型——MWA™具身通用大脑。
在斯坦福大学等顶尖机构联合发起的RoboCasa桌面任务权威测试中,MWA以百分之七十五点二的平均任务成功率刷新了行业纪录,直接拿下了全球第一,把英伟达的GR00T、小鹏的DIAL等一众大厂的主流模型都甩在了身后。

(图源:无界动力)
在这个疯狂内卷的具身智能赛道,无界动力究竟凭什么能虎口夺食?
原因有很多,首先,目前业内流行的,以端到端动作预测为核心的VLA大模型,存在一个本质限制:即静态的视觉-语言预训练并不能够捕捉物理动态与因果关系 ,这就导致模型能力无法泛化,具身智能会被严格限制在训练过的场景中。
为了打破这种限制,以英伟达为首的行业巨头们开始推行世界模型+VLM+VLA的组合,其中VLM负责理解图像和语言,VLA负责把视觉、语言指令转化为动作,世界模型则负责预测环境接下来可能发生什么。
把具身智能拆解为理解、行动和预测,这种做法确实能为现有的机器人添加理解当前状态、预测动作后果的能力,但是过于复杂的真实世界,会让这类世界模型把大量算力放在预测“下一帧画面长什么样”上,显得有些舍本逐末。
而无界动力的MWA走的是另一条路:隐空间世界模型。

(图源:无界动力)
具体来说,MWA模型不需要预测下一帧画面,也不需要还原这个世界的所有像素细节,它专注于在高度抽象的脑内空间里,专门琢磨物体是怎么运动的,以及动作会产生什么后果。
就像人类骑自行车一样, 你骑车时也不会去计算周围树叶的反光和地面的每一道纹理吧,你依靠的是对平衡、重力和摩擦力的直觉。
更厉害的是,它不仅能看懂,还能提前预判。以前的模型是走一步算一步,而MWA具备了长时序推演能力。这就好比下象棋,新手只能看到眼前这一步,而它能在脑子里提前推演出接下来好几步的连贯动作。
理论上,这能解决机器人干细活时动作不连贯、容易出错的老毛病。
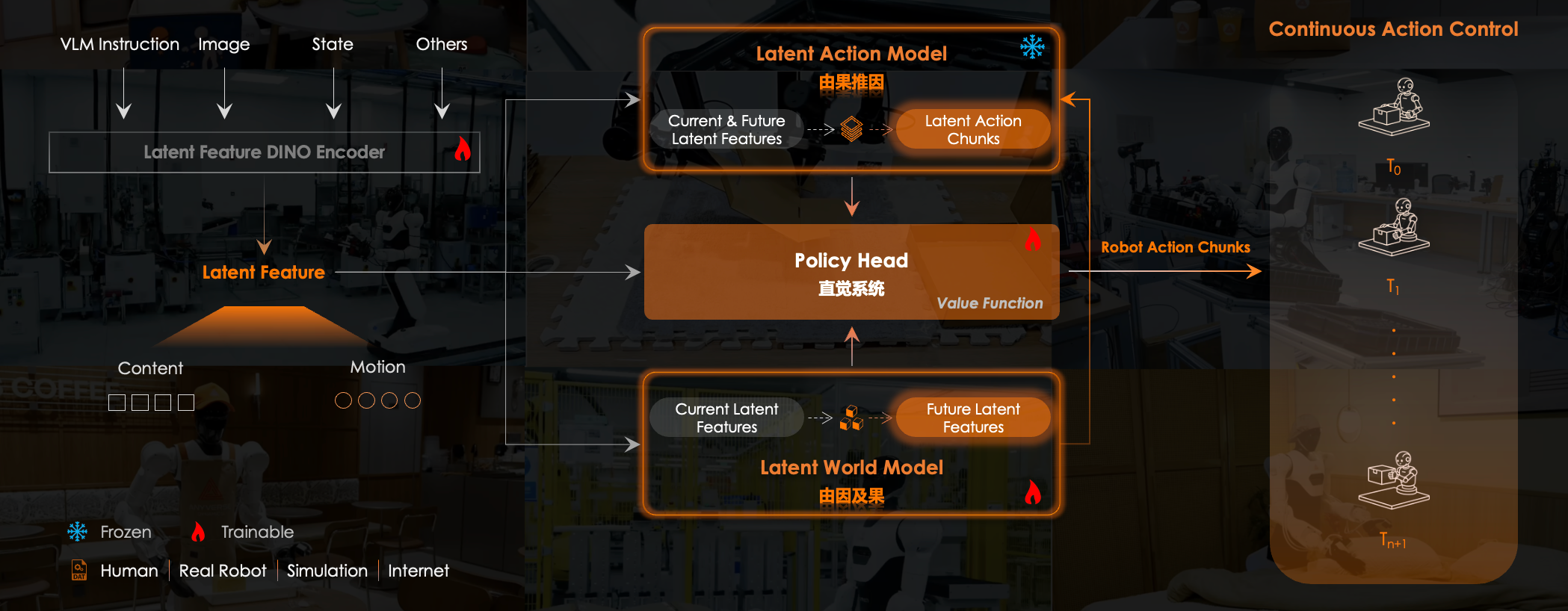
(图源:无界动力)
为了让这个大脑更加聪明,无界动力还搞出了一套非常有意思的训练方法。
市面上的大多数公司都在喂给机器人成功的操作视频,但无界动力却专门建立了一个负样本数据体系,搜集了数万条机器人搞砸了的数据,比如打滑、磕碰、东西飞溅等。
他们不靠人工去给这些失败视频打标签,而是让机器人自己去反思为什么会搞砸。这种在错误中不断试错的方法,让机器人更加清楚自己动作的极限在哪里,也帮助它们建立了一个极其清晰的物理安全边界。
在高精密插接任务的实测中,这种方法的加入让机器人在嘈杂环境下的成功率最高提升了5倍。
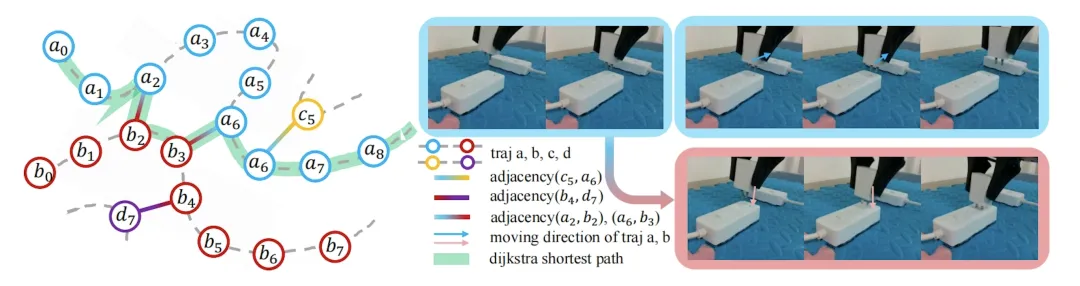
(图源:无界动力)
对比整个行业,MWA确实有其过人之处。它打破了对人工动作标签的严重依赖,环境适应力更强,把它扔到一个极其凌乱的非标准场景房里,它也能靠着自己掌握的物理常识去干活,而不会因为没见过某个特定的盘子就直接宕机。
但热闹看完了,还得看门道。这些拥有聪明大脑的机器人,到底去哪了?
按照官方披露的信息,无界动力已经和远景科技集团签下了一笔超过五亿元人民币的全球市场大单。随着他们的第二代机器人K15即将大批量投产,这些机器人会被送到风电、光伏等能源工厂里,去执行复杂的多步骤装配任务。

而在商业零售领域,他们也已经和国内外知名的连锁咖啡品牌展开合作,让机器人在动态的开放店面里应对各类突发状况。工厂老板和消费巨头们愿意掏真金白银,本质上是对这种技术路线实际作业能力的认可。
总的来说,无界动力这次发布的MWA™隐空间世界模型,确实为具身智能行业带来了一股强劲的新风。它证明了让机器人去理解物理本质,远比让它们死记硬背人类语言要靠谱得多。
但拿下榜单第一,仅仅只是大考的开始。如何让前沿技术转化为你我身边的日常管家,让具身智能真正走入千行百业,还需要无界动力与全球合作伙伴携手努力方可达成。





