



























近日,DeepSeek悄悄上线了一项更新,它在V4版本中引入了推测解码(Speculative Decoding)框架DSpark,并开源了全栈训练库DeepSpec。根据官方的说法,在没有改变核心模型架构的前提下,用户的端到端生成速度提升了60%-85%。
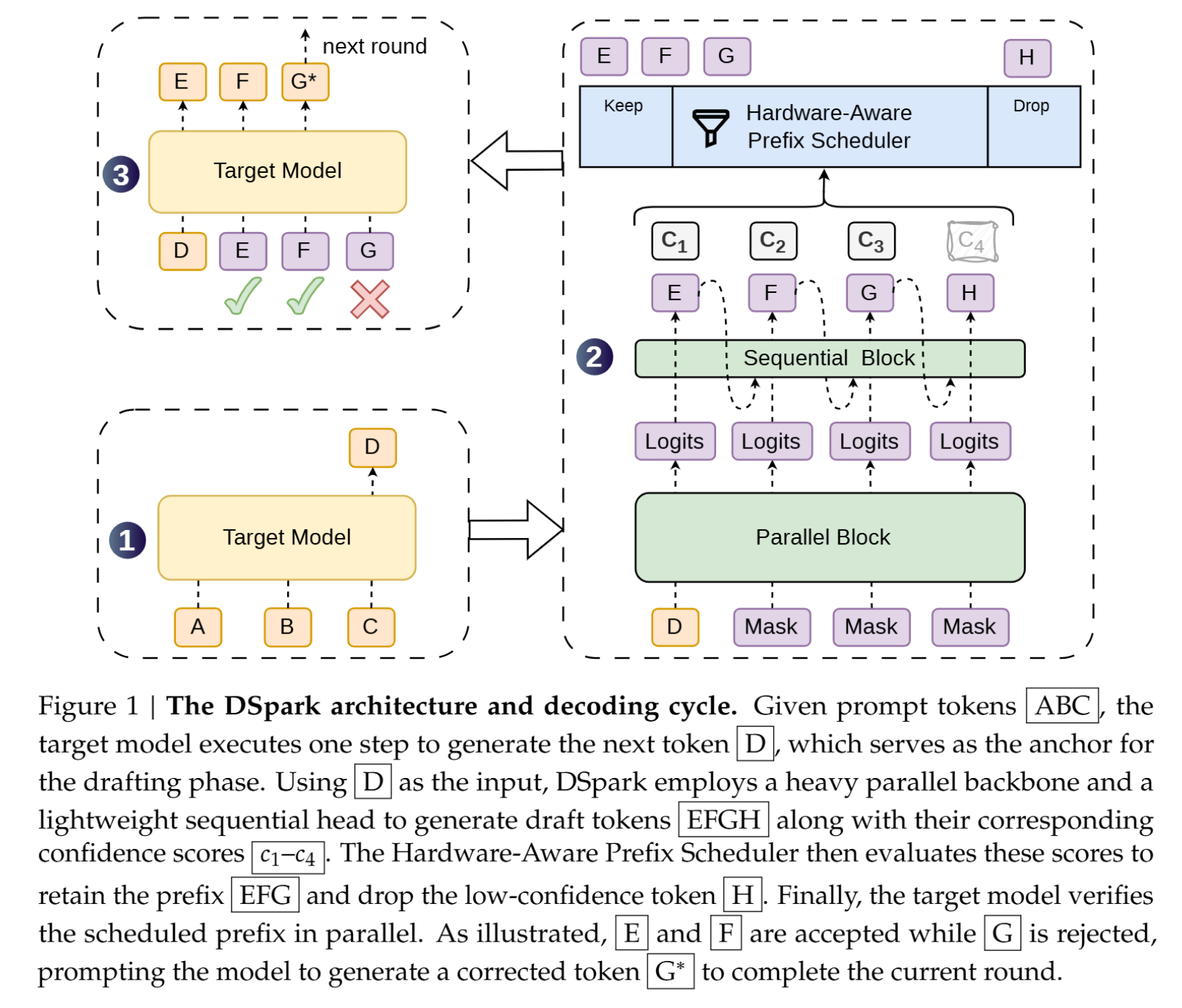
要理解DSpark的作用,首先要理解它是用来解决什么问题的。传统的语言模型输出模式是一个词一个词往外蹦,不仅速度慢,算力利用率还低。
DSpark采用的推测解码相当于给模型配了一个打草稿的助手,助手一口气写下一长段话,主模型再来批量批改。但实际运行时,如果助手经常猜错,主模型批改后推翻重来,反而会浪费大量宝贵的算力。
DSpark的特别之处在于引入了置信度调度等机制,能根据实时的算力负载情况,动态决定草稿打多长,以减少算力浪费,提升推测解码的效率。
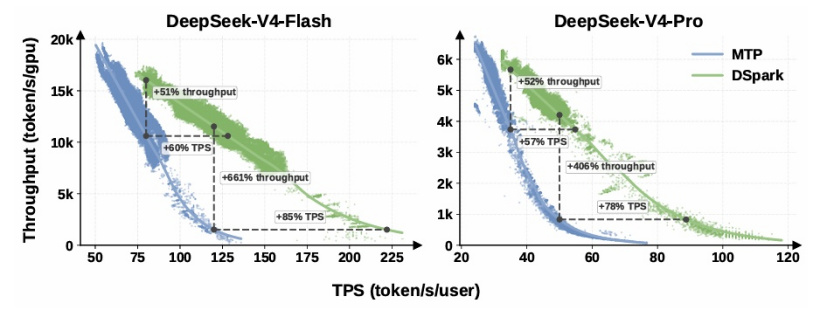
在我们看来,DeepSeek这项技术的落地,正在释放了一个信号:大模型的竞争焦点正从单纯的训练堆料转向推理工程优化。当模型进入真实的生产环境,低延迟和低推理成本才是核心竞争优势。谁能把模型变得轻巧、便宜、快速,谁就能在激烈的模型竞争中拿到更多的订单。
值得一提的是,DeepSeek开源的DeepSpec还支持Qwen3等竞品模型。实际上,这也是一种比较聪明的竞争手段。当前的推测解码技术大多散落在各家实验室中,缺乏标准化,一旦它成为一款被无数人验证了可靠性的标准化工具,DeepSeek的品牌影响力和口碑自然也会上升。

在实际的应用场景中,用户越来越依赖用Agent来解决问题,而越复杂的Agent,要调用的工具和技能也就越多,思考的链路就越长。如果模型的推理速度不够快,运行复杂Agent的效率就会很低,用户的感觉就是等待时间很长、任务完成很慢。
DSpark带来的大幅度提速,对于AI高频交互的场景很有帮助。无论是需要毫秒级响应的实时语音,还是复杂的代码生成,都能借助它来实现效率升级,使得各类复杂智能体有了大规模落地的可能性。
因此,虽然DeepSeek这次带来的不是大模型大版本的更迭,但DSpark的现实意义,可能比新款模型发布更大。





