



























科技圈又爆出重磅炸弹!就在今天,大模型领域的绝对巨佬、Transformer 论文的核心作者 Noam Shazeer 在社交平台上正式宣布:离开谷歌,加入 OpenAI。

(图源:X)
很多人可能对这个名字有些陌生,但他不仅是大牛,更是如今整个生成式 AI 时代的奠基人之一。他是 2017 年那篇改变世界的封神论文《Attention Is All You Need》的共同一作。
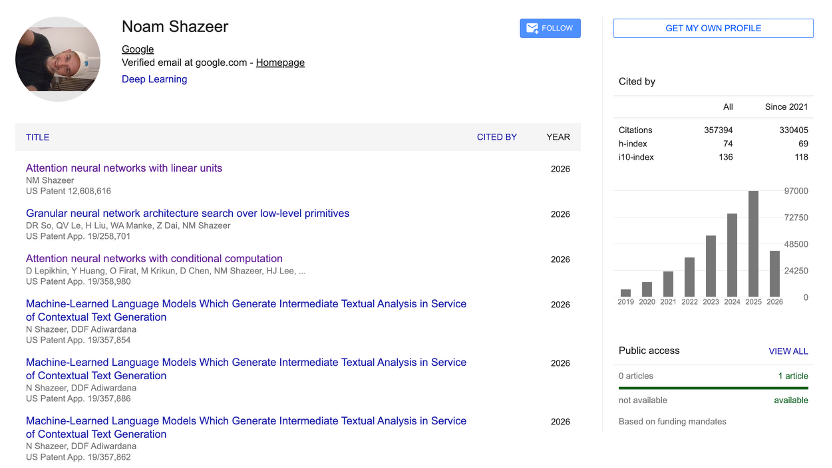
(图源:Google Scholar)
为了让大家直观感受他在学术界和工业界的统治力,可以看看他的 Google Scholar 主页数据,总引用量高达惊人的 357394 次!
Noam Shazeer 和老东家谷歌的关系,也是一绝。
他曾是谷歌的元老级猛将,一手打造了早期的大模型 Meena,但受限于当时的大厂包袱,一气之下于 2021 年离职创办了 Character.AI。
到了 2024 年,后知后觉的谷歌砸下近 27 亿美元把他连人带团队请了回去。
(图源:Linkedin)
其实这两年谷歌在 Gemini 家族的迭代上也算是火力全开,从底层多模态到超长上下文表现都可圈可点,这里面肯定有Noam的功劳在。
结果如今才不到两年, Noam 转头就跳槽去了OpenAI,果然,要走的终究是留不住啊。对谷歌来说,这波简直是赔了夫人又折兵,一口老血喷出来。
现阶段的大模型,在核心能力上已经很难拉开巨大的差异,反而是在应用端、算力端需要快速提升,因为烧tokens的路线在经济帐上明显算不过来。
仔细看看Noam今年的最新专利,这里面藏的全是大模型下一阶段演进的最核心命题:
Agent的终极拼图:专利US20260037744A1明确提到了使用结构化工具(如 API)。这意味着它的核心不仅是内部推理,更是让大模型具备自主调用外部工具、API 的 Agent 能力。OpenAI 显然需要他来补齐打造“超级智能体”最关键的一环。
用 AI 设计 AI: 专利US20260105300A1揭示的是神经架构搜索(NAS)
。这说明他不仅懂宏观设计,更在研发用算法去自动搜索和拼装比现有 Transformer 更高效的底层网络组件。 榨干算力与硬件性能:专利 US20260044710A1正是大名鼎鼎的混合专家模型(MoE)核心逻辑;而另一项带有 linear units 的专利,则是通过引入元素级乘法来优化底层前馈网络(如业界大火的 GLU 变体)。
总结来说,OpenAI 拿下 Noam,看中的是他底层构建的能力。
大家觉得 Noam 的加入,能帮 OpenAI 继续稳坐铁王座吗?欢迎在评论区聊聊你的看法!





