



























“递归”这个词,最近突然在AI圈子里火了。
两家初创公司直接把这个词当成了公司名,许多实验室开始在路线图里塞进一个叫做RSI的三字缩写中,也就是递归的英文名——recursive self-improvement(递归式自我改进)。就像AGI一样,RSI正在变成一个让人既兴奋又忐忑的行业暗号,哪怕大家对它的定义还没完全对齐。
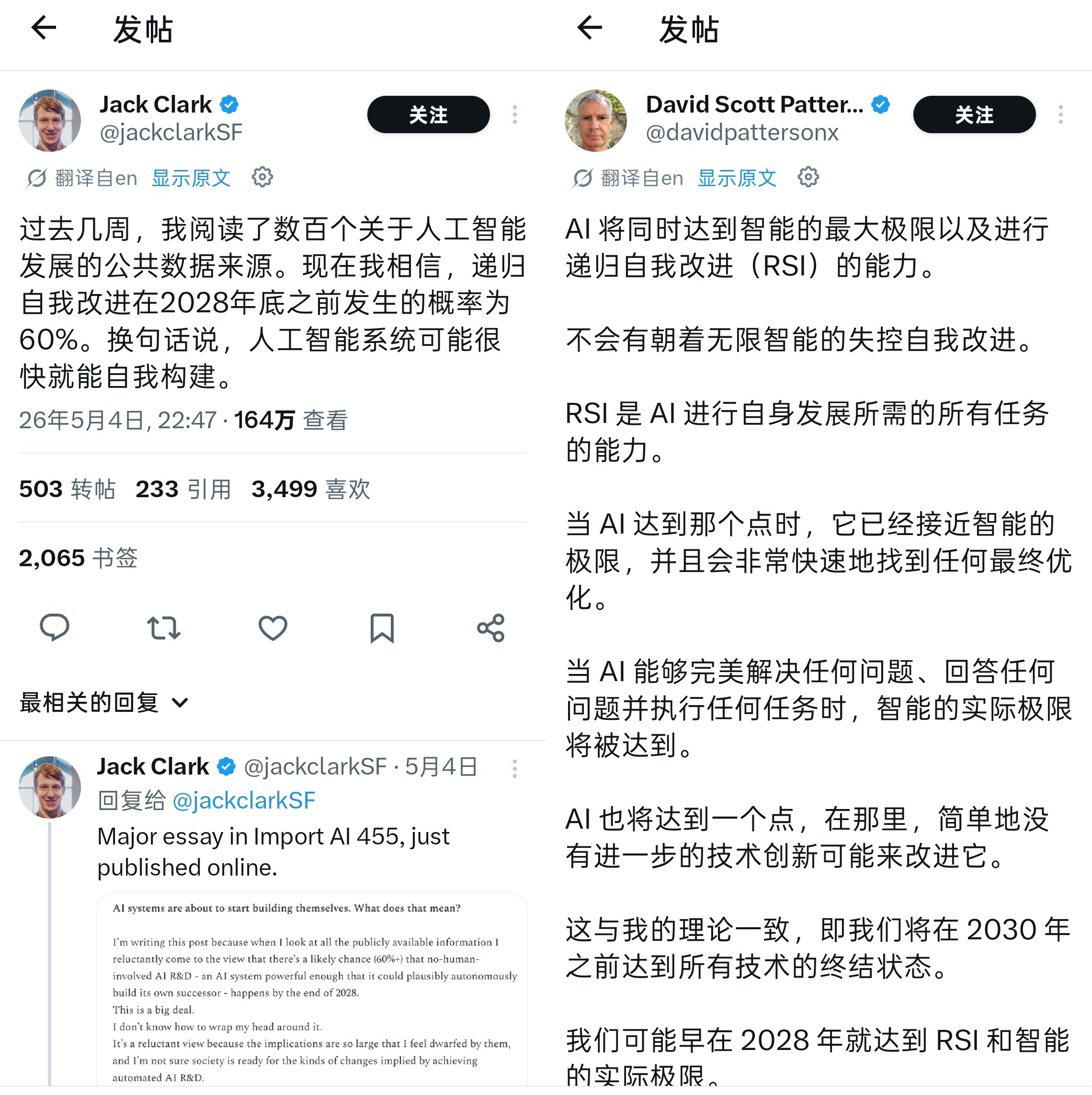
(图源:X)
什么是RSI?简单来说,就是让AI自己训练自己,在技术界,RSI一直被视为人工智能进步的主要标志之一,与记忆、推理和多模态并列,唯一的限制是算力,人类在其中已经不是必要条件,甚至连帮手都算不上。
听起来很科幻,或者说,听起来很危险?但冷静下来想,这不是AI行业的第一次狂热。从2016年的AlphaGo到2023年的ChatGPT,再到今天各家大模型参数军备竞赛,AI行业的天性就是追逐下一个“改变一切”的东西,在雷科技AGI(ID:leikejiagi)看来,RSI可能就是下一场狂欢。
RSI火了:当AI能靠「递归」进行自我构建
今年5月,AI界知名研究员Richard Socher高调创办了一家叫Recursive Superintelligence的新公司,名字直接就是RSI。
他表示:“我们的核心目标是构建真正意义上的递归自我改进超级智能,整个研究的构思、实现和验证过程,全部自动完成。”
另一个更让圈内人津津乐道的案例,是安德烈·卡帕西(Andrej Karpathy)推进的一个叫Auto-Research的项目:用智能体集群来训练语言模型,让模型自己做简单的研究任务,自己去改进自己。
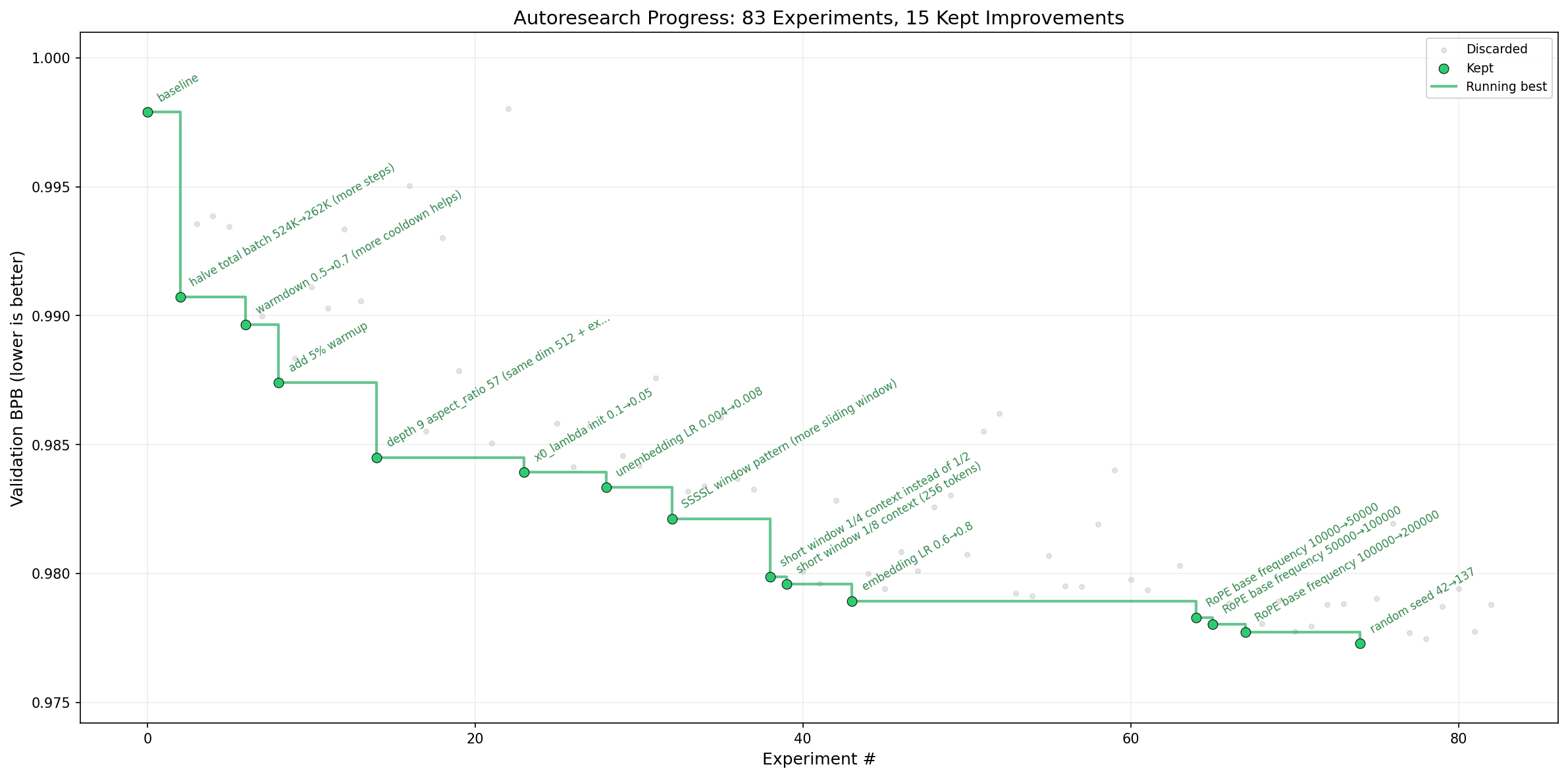
图源:github
安德烈·卡帕西也是一个传奇人物,他在特斯拉做自动驾驶、在OpenAI做GPT都留下过硬货。现在他把RSI当成下一站来all in,而且是用公开透明的方式在推进,这也说明他是真的认为这事可以做到。
有意思的是,他对这个项目出奇地坦诚,定期在推特上更新进展,代码也开了GitHub公开仓库。当然,安德烈·卡帕西自己也说了,目前的工作还是在GPT-2级别的小模型上做迭代,“还不是什么突破性研究(暂时)”,但这已经足够带动一大批研究者跟进了。
更重要的是,安德烈·卡帕西最近加入了Anthropic的预训练团队。Anthropic有Claude,卡帕西有auto-research这套方法论,两边一合,大模型+自训练循环,一旦跑通,就不是GPT-2级别的小打小闹了。

图源:haimagazine
另一家叫Adaption的公司推出了一个AutoScientist工具,目标是自动化前沿模型的训练过程。逻辑跟安德烈·卡帕西的auto-researchers一样,训练agent做渐进式改进。只不过Adaption的野心更大,想直接搞定一整个全尺寸前沿模型的训练闭环。
这两家其实代表了两种路线:安德烈·卡帕西是从底层逐块验证,一边开源一边在社区里攒势能;Adaption是直接冲着商业化的大模型训练场景去的,落地意愿更强烈。两条路谁先跑通,对整个行业的影响会截然不同。
Google CEO泼冷水:我们还没到那一步
关于RSI,AI圈大佬们也众说纷纭。
Google CEO 桑达尔·皮查伊上个月在一档播客里,措辞相当谨慎地承认了现实:“(RSI)是一个连续体,我们确实都在进步。但如果按照大家描述RSI的方式,那代表的是下一个量级的加速,会有很多影响,但我们还没到那一步。”
虽然如此,但这里面的“连续体”描述,已经包含了不少让人细思极恐的事情。
今年1月,Anthropic一位主导Claude Code开发的程序员坦言,团队里接近100%的代码是Claude Code写的,这是一种字面意义上的AI在写自己。不是AI辅助工程师写代码,而是AI工具在某种程度上已经在替代工程师写自己的代码。
图源:Anthropic
Anthropic有一份关于Mythos预览版本的内部调查:18位工程师里,有5位认为,如果配套系统再改进一下,这个版本的Mythos就可以替代一个L4工程师,即可以独立承接复杂项目、不需要实时监督的中级程序员。
但缺陷也写得很清楚:“Claude报告的主要弱点包括:管理周期以上的模糊任务、理解组织优先级、品味、验证、指令遵循和认识论。”意思就是说,它弱的,恰恰是自我驱动的那些事,而自我驱动,是RSI的根基。
好玩的是,Georgetown安全与新兴技术研究中心(CSET)去年组织了一批专家专门研究RSI。这群专家在评估时出现了明显分裂,一部分人预期即将迎来“超级智能爆炸”,另一部分人预期进展会更慢、最终会触达某个瓶颈期。
但他们有一个共识:递归,让未来变得格外难以预测。
为此,METR研究员Ajeya Cotra的一篇文章,把RSI的进程拆解成几个里程碑,我觉得这是目前最好用的分析框架。
第一级叫“足够”(adequacy):把人类完全移除后,系统依然能做研究——哪怕不如人类,但能运转。
第二级叫“对等”(parity):AI独立完成的研究,和人类独立完成的研究质量相当。
第三个叫“超越”(supremacy):AI独立系统的表现,超过了人类与AI协作的系统。
有点像自动驾驶里的L2、3、4、5。Ajeya Cotra的判断是:我们离第一级已经很近了。但第二级什么时候来,她没给时间表,但她给了一个非常明确的推演,一旦第二级到来,后续加速会远超过往,“一年之内可能就会冲到第三级。”
为什么这么快?因为到了第二级那一刻,AI就变成了一个不需要睡觉、不需要开会、不需要对齐KPI的研究团队。它可以24小时不间断地试、改、再试。而人类做研究,哪怕效率再高的人,一天的有效深度工作时间也就那么几个小时,中间还夹着无数打断和沟通成本,一旦这个瓶颈不存在了,加速度是断崖式上升的。
国内没人喊RSI,但DeepSeek们已摸到了边
前面聊了一堆海外的进展,你可能想问:国内呢?
坦白讲,国内厂商很少公开喊RSI,海外的AI公司能把“递归超级智能”写进公司使命,这种事在国内几乎不可想象。但如果说让AI自己改进自己,国内厂商其实已经在不同的路径上悄悄摸到边了。
最典型的例子是DeepSeek。他们花的钱比OpenAI少一个数量级,但在很多推理任务上已经可以正面刚。靠的就是算法效率的极致优化——MoE架构、激活参数的极致压缩、训练策略的工程化打磨。
虽说这跟RSI关系不大,但这是一条用更聪明的方法,替代蛮力堆算力的路。而这条路,恰好是RSI的核心逻辑之一:让模型在迭代中找到更聪明的那条路径。
百度文心这边,强化学习驱动模型自我优化已经是常规操作了。虽然没有用RSI这个名字,但做的是同一件事:让模型在特定任务上通过自反馈循环不断改进。从这个角度看,国内厂商不是没在做RSI,只是他们已经把RSI的某些环节变成了日常工程实践,只是不挂这个名。

(图源:gemini生成)
当然,差距也是客观存在的。OpenAI和Anthropic的人才密度,目前国内任何一家都还比不了,这意味着在RSI的探索上,眼下仍然是跟随状态。
但历史经验告诉我们,国内厂商在“管道路径明确之后”的追赶速度往往是惊人的。RSI的框架正在被海外大神们拆得越来越清晰,Karpathy的代码也公开在GitHub上,一旦可复现的路径走通了,国内玩家的成本控制能力和落地场景密度,会是一个被市场严重低估的变量。
但同时,我们也得适当泼点冷水。事实上,AI自己生成的数据,用来训练下一版AI,质量是会往下掉的。RSI的逻辑是AI生成好的数据,然后用这些数据训练下一代AI,使得下一代AI更强。
而实际情况可能反过来,AI生成的数据里往往会混进它自己的幻觉、偏见、质量退化,这些二手数据被喂给下一版,下一版再产出更差的三手货,循环几代之后整个系统就塌了,就像一个复印机不断复印复印件,印到第十张脸都糊了。
学术界管这个叫模型坍缩,已经有论文验证过这个现象真实存在。
再者,RSI需要的理想环境,在真实世界里根本不存在。这套系统要跑起来,两个前提缺一不可:无限算力、全球开放协作的研究生态。
而现实是训练一个前沿模型的成本已经到了十亿量级,芯片产能有限、能源有限、优质数据也在变少,出口管制和技术脱钩正在把AI研究切成几个互相不流通的圈子,人和货都流不动,连这些基础条件都凑不齐,就别谈什么RSI了。
RSI不只是一个技术问题了,它还需要一个足够开放的世界,而这个前提能不能成立,技术圈还真无法说了算。
写在最后
最后说个我觉得有意思的观察:整个行业在过去五年里,先是大规模预训练把人拉进了“参数崇拜”,然后是RLHF(基于人类反馈的强化学习)让人相信“价值观可以微调”,现在是RSI在讲一个“机器自己跑完整个研发链条”的故事。每一步都在让人类往后退一步,不是退出行业,而是退出决策链条。
虽说这种退法不一定是坏事,但它是不可逆的。一旦某个环节被自动化接管了,人的直觉、经验、判断力在那个环节就慢慢退化了,就像不用GPS之后你会发现认路能力确实在变差。
到那时候,我们连工具是怎么造出来的,都不一定能真的理解。





