



























2026年4月,具身智能行业迎来一个极具分水岭意义的关键节点。
特斯拉选择公开其Optimus第三代灵巧手的核心硬件专利。这种开放,延续了特斯拉一贯的硬件开源逻辑:通过释放关键能力,推动行业形成统一标准,从而加速产业整体进化。
但几乎在同一时间,全球生产力型通用智能机器人领跑者智平方正式发布AlphaBrain Platform,一个面向全球开发者的一站式具身智能模型开源社区。
与硬件层面的开放不同,AlphaBrain Platform直接指向机器人的核心——“大脑”。它不是开放一个零部件,而是开放一整套让机器人能够理解世界、做出决策并持续进化的大脑体系。
如果说特斯拉在回答“机器人如何被制造”,那么智平方正在回答一个更关键的问题:
机器人如何变得真正聪明。
这是智平方对行业未来方向一次强有力的清晰表态,也是一家中国公司对特斯拉硬件开源的更高维度回应!

开源模型很多,真正“好用”的很少
过去几年,具身智能领域不缺模型,也不缺论文。但一个尴尬的现实是:开源模型很多,真正“好用”的很少。
很多开源项目停留在“能跑通”的阶段。开发者想做真正的创新,往往要从数据处理开始,一路搭建训练流程、对接不同模型、手动完成评测验证。不同项目之间数据格式不统一、接口不兼容,大量时间消耗在重复的工程工作中。
开发者面临的核心问题始终是:这个模型怎么跑起来?那个模型跟它比谁更强?我的创新能不能落地?
智平方本次联合港科大(广州)熊辉团队推出的AlphaBrain Platform,改变的正是这一点。它不是简单开源一个模型,而是把“数据—训练—模型—评测”整条链路全部打通。更重要的是,它一次性开源了当前具身智能领域最前沿的三条技术路线,包含三大“全球首创”。
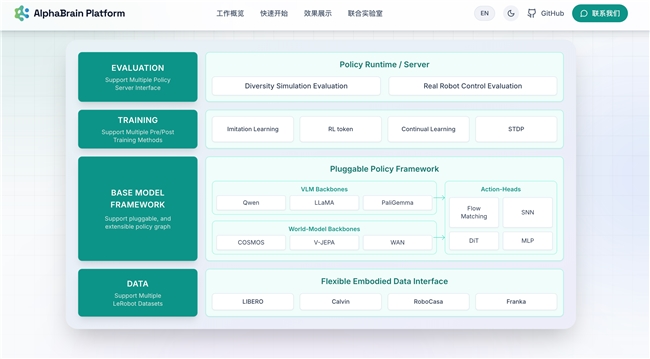
三大“全球首创”集中开源:类脑模型、RL Token、世界模型我全都要!
全球首个开源类脑VLA模型(NeuroVLA)
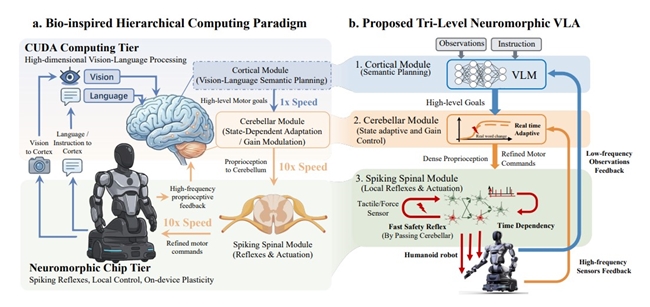
类脑模型被公认为VLA(Vision-Language-Action)的未来方向。传统VLA模型“训练完成即固定”,无法在部署后继续学习。智平方首次在类脑控制任务上达到前沿水平,开源了NeuroVLA——一种可以在真实环境中持续适应的类脑系统。
NeuroVLA引入脉冲神经网络动作头与R-STDP训练算法,支持部署阶段的在线自适应,使用前向传递方式,让机器人具有肌肉记忆能力。这意味着机器人第一次从“执行指令的工具”转向“在任务中不断进化的主体”。它不只是完成任务,而是在过程中变得更熟练、更稳定,接近人类的学习方式。
推动具身智能向生物脑学习机制迈进——真正的智能不是训练出来的,是进化出来的。
全球首个基于RL Token的开源VLA训练架构
RL Token是“强化学习 + VLA”的黄金组合,也是让大模型真正可落地的场景化利器,其核心是将大模型的通用认知与强化学习的特定场景优化能力深度融合,形成了一种既能理解复杂意图,又能通过与环境交互持续精进执行策略的智能体架构,从而让大模型从“纸上谈兵”的对话工具,真正转变为能在工厂、家庭、仓库等具体场景中完成实际物理任务的自主系统。但长期以来,对 VLA 做强化学习面临着算力门槛高、容易灾难性遗忘等难题。
智平方率先在LIBERO环境上完成验证,并提出优化方案。其信息瓶颈编码器与两阶段训练策略,使VLA主体在RL微调过程中完全冻结,既避免灾难性遗忘,又大幅降低训练计算成本。所需训练参数从 3.9B 降至约 137M(占 VLA 的 3.5%),其中RL 梯度更新仅涉及1.3 M参数,仅需单张4090显卡即可进行强化学习后训练。
这意味着开发者可以在不破坏原有能力的前提下优化模型。模型可以像人类一样在已有经验基础上精进,而不是反复推翻重来。这种“稳定进化”的路径,为通用具身智能提供了真正可持续的训练方式。
世界首个可插拔世界模型架构(WA)
世界模型是当前最火的“想象力引擎”——让机器人在行动前预演未来,做出更优决策。然而,世界模型的研究长期停留在论文阶段,不同模型之间难以对比、难以集成。
智平方首次实现世界模型的可插拔化。平台原生集成NVIDIA Cosmos Policy原始权重,同时支持Cosmos、Wan、 V-JEPA三大世界模型Backbone一键切换,共享统一动作解码器。不同世界模型可以在同一任务中直接切换、对比与验证。
这意味着机器人可以在行动前“预演”多种可能路径,选择最优解。这种能力本质上是在为机器人补上“思考”的一环。 开发者可以自由对比不同世界模型的表现,极大降低研究门槛——这一长期停留在论文中的能力,终于成为人人可用的工具。
除了上述几张王牌,AlphaBrain Platform还提供了首个面向跨架构 VLA 的开源持续学习算法。大模型在学习新技能时极易产生“灾难性遗忘”——学了新动作忘了老技能,且微调成本极高。智平方通过这套算法,突破了架构兼容性的瓶颈。
五大优势,构建完整技术壁垒
除了三大前沿方向,AlphaBrain Platform还以完整的五大优势构建起难以复制的竞争壁垒:
技术最前沿:集成世界模型、类脑模型等最前沿技术路线,开发者无需从零复现论文。
覆盖面最广:同时支持RL、世界模型、传统VLA、类脑模型,业内唯一覆盖所有主流技术方向。
组合最自由:不同架构、训练范式可自由组合,跨领域“化学反应”只需修改几行配置。
对比最公平:统一数据格式、评估环境、测试标准,覆盖LIBERO、RoboCasa、CALVIN、BEHAVIOR-1K等8大主流Benchmark,一键评测,好模型不再靠“嘴强”。
最广泛开发社群:集合全球顶尖机构的开源力量,覆盖学术界与产业界,共建具身智能开放生态。
以前,开源一个模型是给你一个工具。现在,AlphaBrain Platform直接给你一个“顶配全家桶”——最前沿的模型、最趁手的工具、最标准的评测,一次配齐,开箱即用。

为什么是智平方?“最像特斯拉”的中国机器人公司
在机器人圈,有一个标签正在被越来越多的人提起:智平方是最像特斯拉的中国机器人公司。
为什么?因为特斯拉有三样东西同时强:模型、硬件、商业。智平方,恰好也是这三样全强。
模型强:作为全球具身智能大模型的领跑者,智平方自主研发的 AlphaBrain,致力于为通用智能机器人提供“最强大脑”,被摩根士丹利列为具身基础模型的代表企业。2024年,公司发布创业公司首个VLA模型,在模型规模仅为谷歌同类模型1/20的情况下,性能提升超过80%。2025年4月发布快慢系统深度融合的VLA大模型,超越Pi0达30%。2025年11月率先推出世界模型与VLA融合的Video2Act,在第三方评测中较硅谷标杆领先超30%。如今,智平方再次引领突破——开源了全球首个类脑VLA模型(NeuroVLA),并将其融入AlphaBrain。持续领先、代际碾压,是智平方模型能力的真实写照。
硬件强:自研机器人本体,核心部件无故障运行时间超过5万小时,达到工业级可靠性标准。自建产线量产,2000台年产能支撑2026年交付。

商业强:已落地汽车、半导体显示、生物制造、公共服务、新零售等十余个高价值场景,单一订单体量居全球具身行业第一(摩根斯坦利报告),率先跑通“数据×商业”双闭环。

而这次AlphaBrain Platform的发布,更是把“全栈能力”四个字写在了明面上。别人开源是一个模型,智平方开源是一个“顶配全家桶”——三大“全球首创”,一次交付。只有全栈能力强的公司,才有能力做“全链路”的开源。
从开源能力到定义生态:行业的真正竞争才刚刚开始
过去,具身智能的竞争主要集中在“模型能力谁更强”。但随着技术演进,这种竞争正在快速演变为“谁能构建更强的生态”。模型可以被追赶,而生态一旦形成,就会产生持续的积累与放大效应。
AlphaBrain Platform正是在这一关键阶段出现的核心变量。它不仅开放能力,更定义了能力如何被使用、如何被比较、如何被持续优化。智平方不再只是参与技术竞争,而是在主动构建整个行业的“基础设施”。这种能力,本质上就是“定义权”。
特斯拉通过开源硬件,推动机器人“身体”的标准化;智平方通过开源“机器人大脑”,推动机器人“智能”的标准化。前者解决“如何制造”,后者决定“如何进化”。前者推动产业的起点,后者决定产业的上限。
当越来越多公司能够造出机器人之后,谁能让机器人更快学习、更好理解世界、更稳定地完成任务,谁就能在未来占据主导位置。
AlphaBrain Platform的出现,标志着具身智能正在从“少数团队的技术竞赛”走向“整个生态的协同进化”。当最前沿的能力向开发者开放,当创新门槛被显著降低,技术进步的速度也将随之改变。
当“大脑”被打开,行业才真正开始。 这也正是智平方对具身智能时代意义深远的一次贡献:以开源之力,重塑智能的演进规则。





